MySQL SQL加锁分析
本文将介绍不同SQL语句的加锁分析,TL;DR
简单加锁情况
Update操作加锁流程
- MySQL server根据where条件,读取第⼀条满⾜条件的记录
- Innodb引擎将第⼀条记录返回,并加锁(current read)
- MySQL server收到这条加锁的记录之后,会再发起⼀个Update请求,更新这条记录
- 备注:针对当前读的SQL语句, Innodb和Server交互,是⼀条⼀条记录进⾏的;加锁也是⼀条⼀条进⾏的 ,两阶段锁2PL:集中加锁和集中解锁
2PL: Two-Phase Locking
- 锁操作分两个阶段:加锁阶段和解锁阶段,并且保证加锁阶段和解锁 阶段不相交
- 加锁阶段:只加锁,不放锁
- 解锁阶段:只放锁,不加锁
简单SQL的加锁分析
-
select * from t1 where id = 10
- MVCC多版本控制, Select 快照读,不加锁
-
delete from t1 where id = 10,有什么问题?类似update也有相同的问题
- id列是不是主键?
- 当前系统的事务隔离级别是什么?
- id列如果不是主键,那么id列上是否有索引吗?
- id列上如果有⼆级索引,那么这个索引是唯⼀索引吗?
- SQL的执⾏计划是什么?索引扫描?全表扫描?
-
下面针对👆的疑问进行拆解,有如下几种组合:
- id主键+RC隔离级别
-
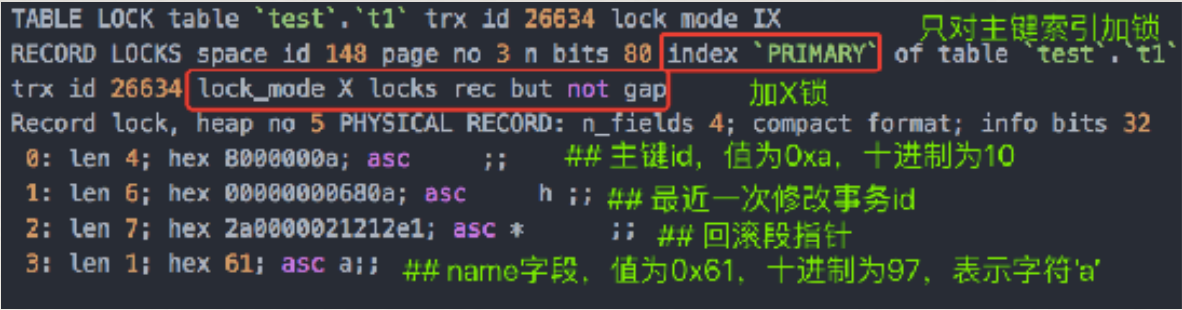
场景:id是主键, SQL为delete from t1 where id=10
-
结论:id主键,此SQL只需要在id=10这条主键索引上加X锁
- id唯⼀一索引+RC
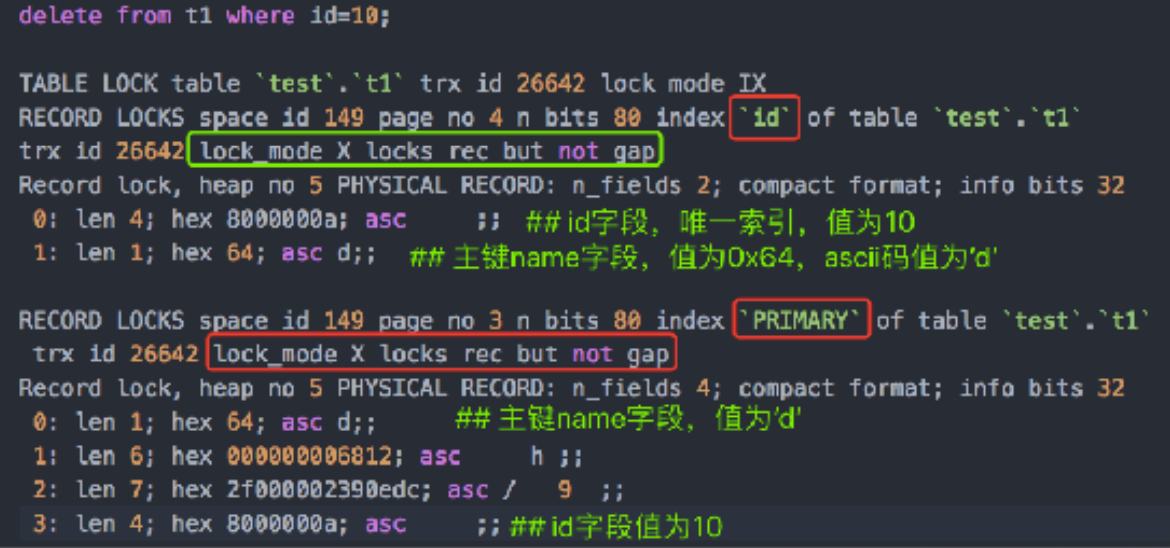
- 场景: id是⼆级唯⼀索引, name是主键, SQL为delete from t1 where
id=10
* 结论:若id列是唯⼀索引列,那么SQL需要加两个X记录锁--UK & PK
-
id⾮非唯⼀一索引+RC
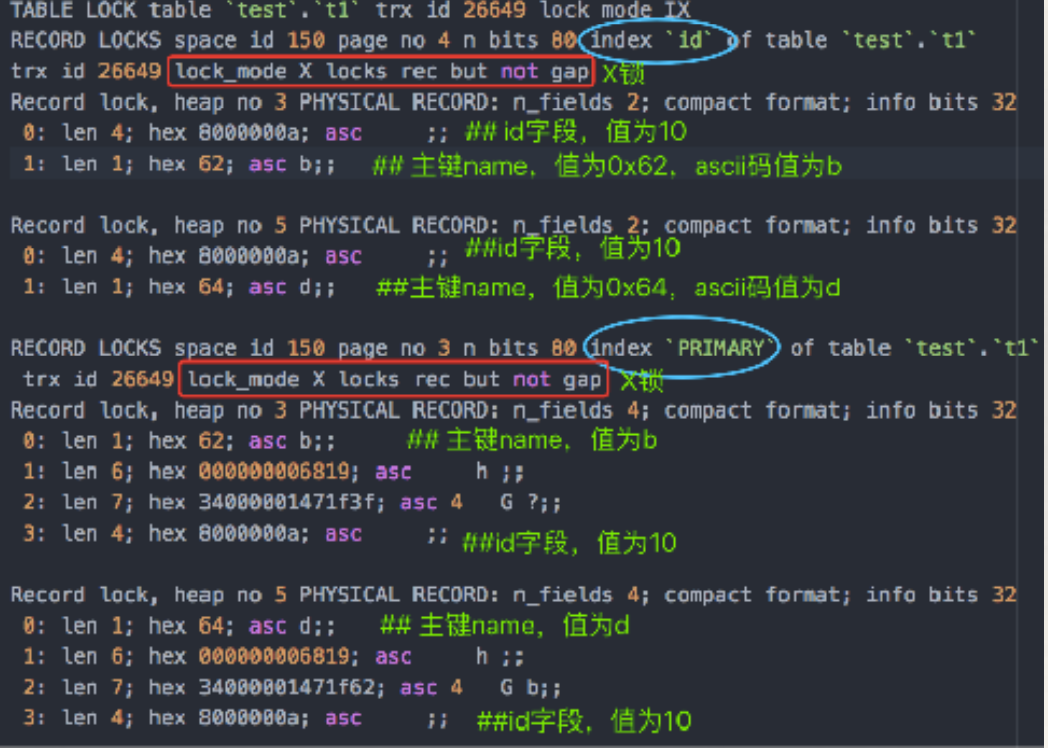
- 场景: id是⼆级⾮唯⼀索引, name是主键, SQL为delete from t1 where id=10
- 结论:若id列是⾮唯⼀索引列,那么SQL满⾜的查询条件的索引记录都会被加锁
-
Id没有索引+RC -Server优化
-
场景: id是没有索引, name是主键, SQL为delete from t1 where id=10
-
结论:若id列是没有索引, SQL会⾛聚簇索引全表扫描,对每条记录都加X记录锁
-
MySQL Server的优化 在server过滤条件,发现不满⾜后,会调⽤unlock_row⽅法,把不满⾜条件的记录放锁(违背2PL的约束)。 不满⾜记录条件的记录上加锁/放锁动作不会省略
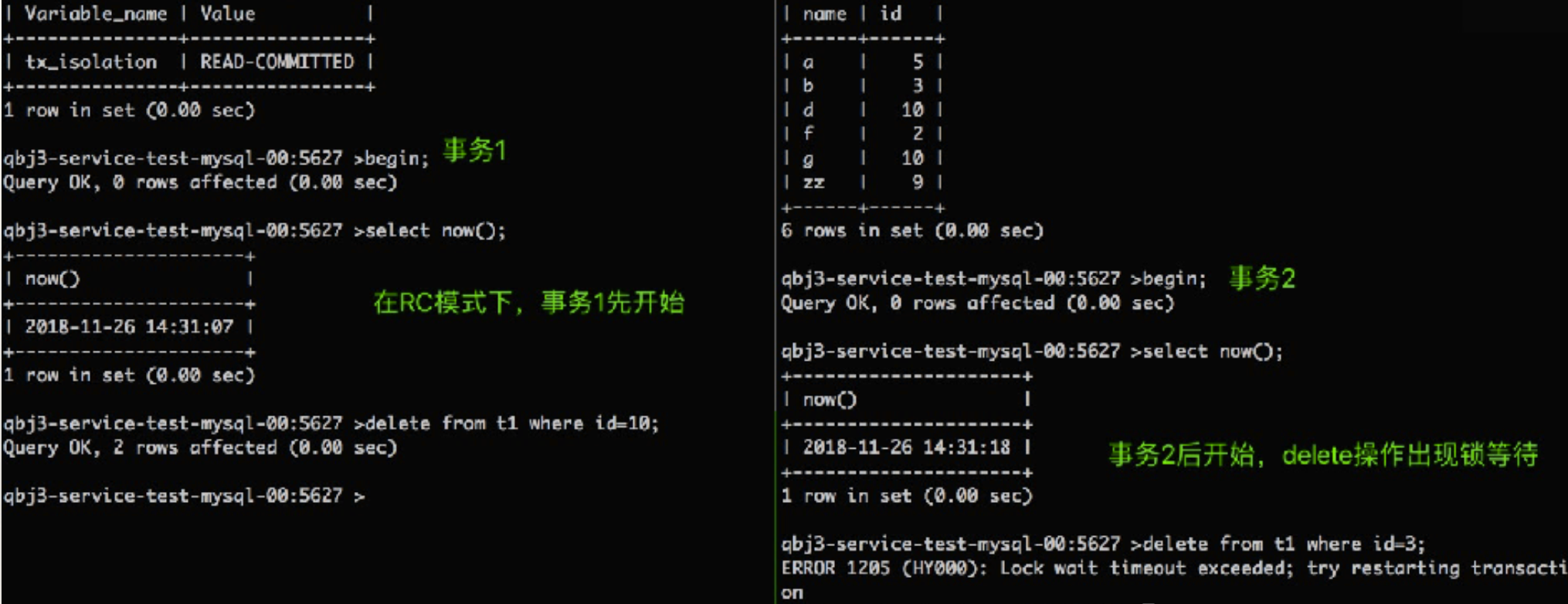
* delete有锁等待,同等实验,update没有锁等待
- id主键+RR
- 场景: id是主键, SQL为delete from t1 where id=10
- 结论: id主键,此SQL只需要在id=10这条主键索引上加X锁
- id唯⼀一索引+RR
- 场景: id是⼆级唯⼀索引, name是主键, SQL为delete from t1 where id=10
- 结论:若id列是唯⼀索引列,那么SQL需要加两个X记录锁
- id⾮非唯⼀一索引+RR
-
场景: id是⼆级(⾮唯⼀)索引, name是主键, SQL为delete from t1 where id=10
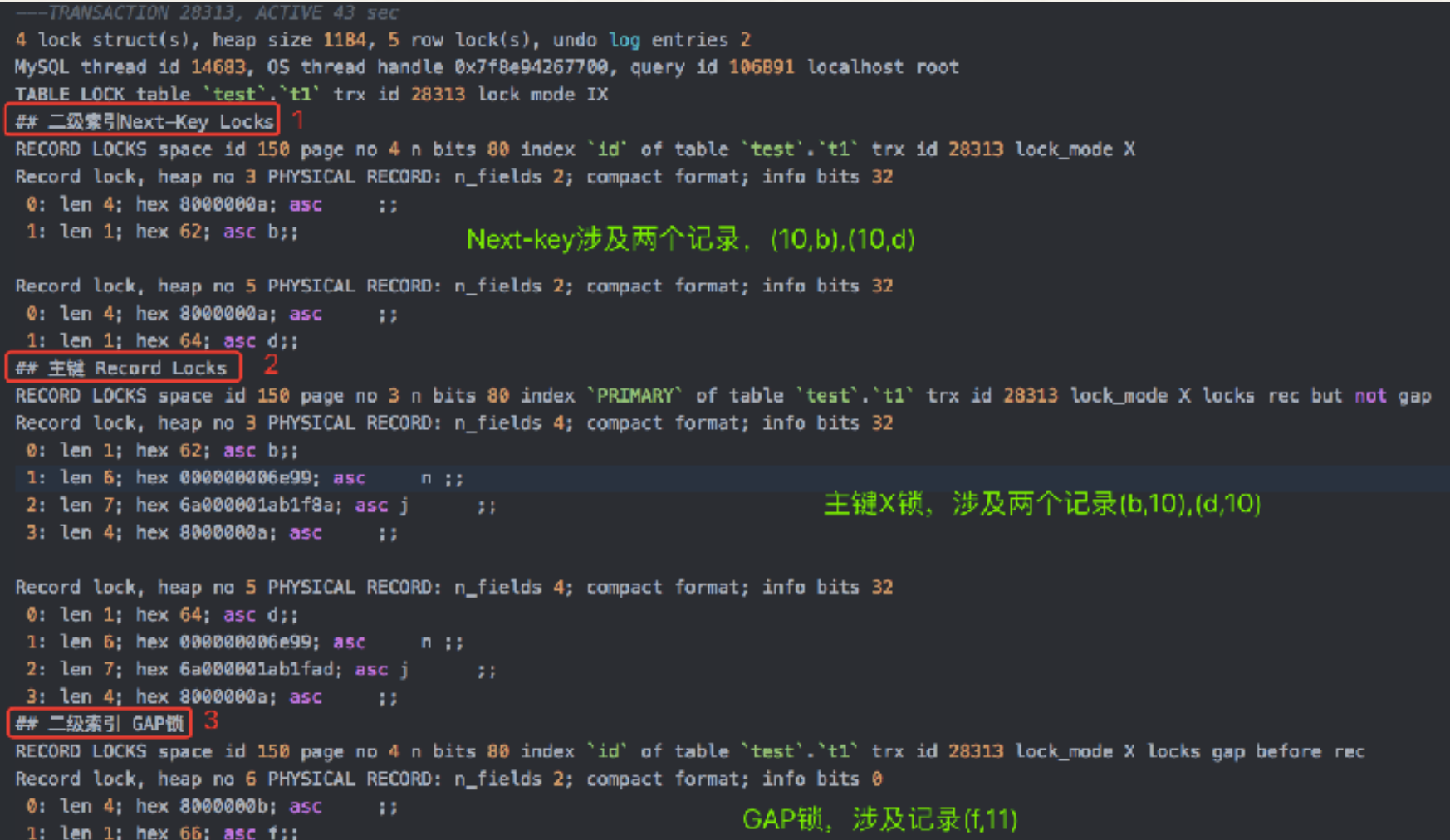
-
通过id索引定位到第⼀条满⾜查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后通过主键聚簇索引上的记录加X锁
-
读取上⼀条,和上⼀步骤⼀样加锁,直到进⾏到第⼀条不满⾜条件的记录[11,f],此时,记录不需要加X锁,需要加GAP锁
-
RC和RR区别在于GAP锁
- id没有索引+RR
-
场景: id是没有索引, name是主键, SQL为delete from t1 where id=10
-
结论:若id列是没有索引, SQL会⾛聚簇索引全表扫描,对每条记录都加X记录锁。聚簇索引每条记录间的间隙添加GAP锁
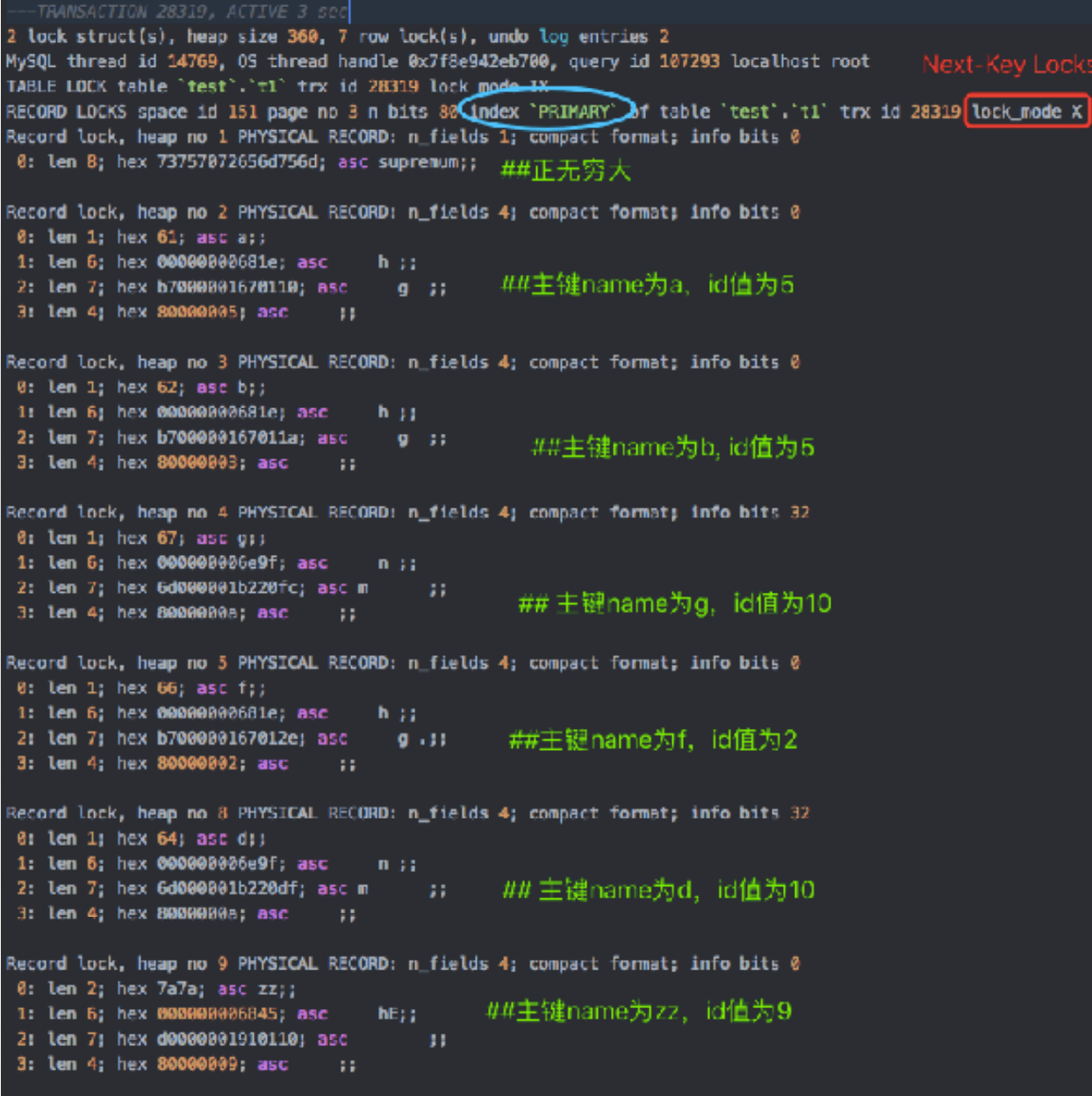
-
SQL全扫描,所有记录都加Next-Key Lock,将阻塞所有写⼊
- Serializable
- 针对当前读的操作,和RR模式⼀样
- 针对快照读,使⽤加读锁模式, MVCC并发控制降Locked-Based并发
复杂SQL的加锁分析
补充概念:
-
关系型数据库中的数据组织
-
表
- 堆表(所有的记录⽆序存储)
- 聚簇索引表(按照记录主键进⾏排序存储)
-
索引
- 完整记录的⼦集,⽤于加速查询
- 组织形式,⼀般为B+树结构
-
-
下面是示例Table定义
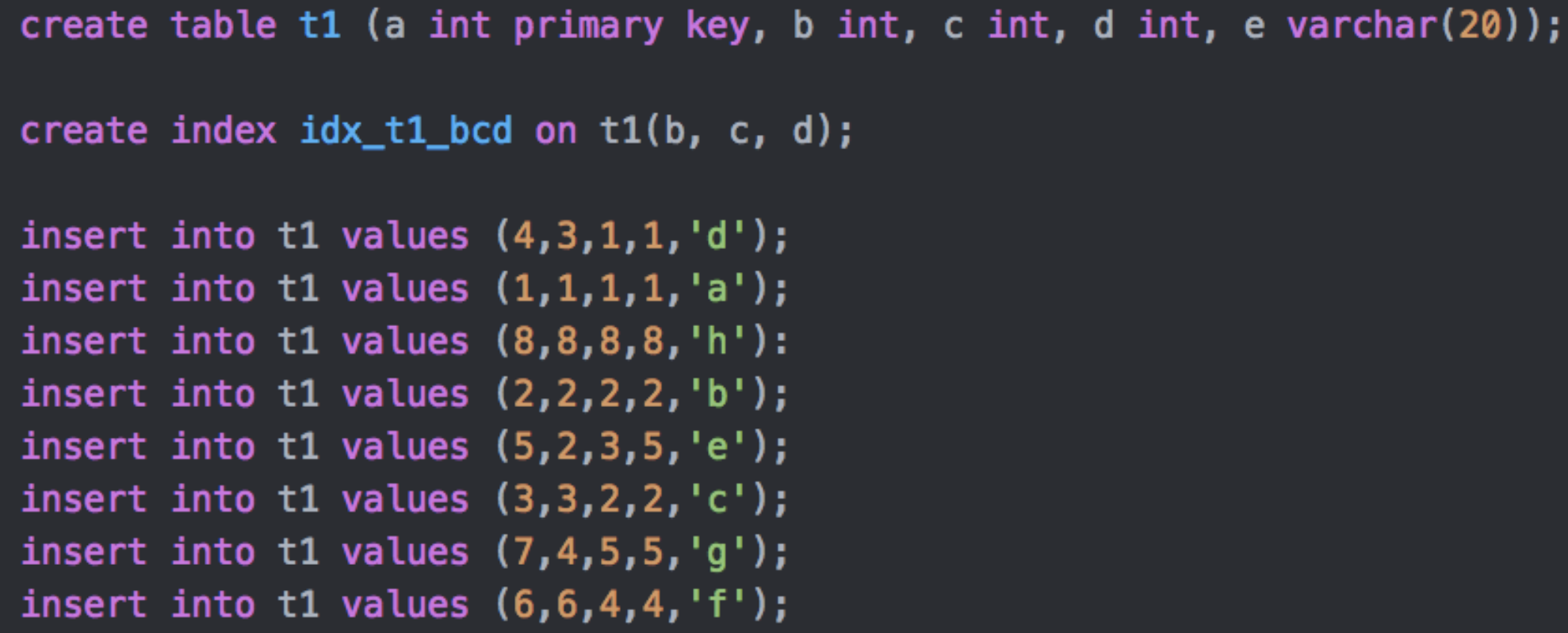
Where条件在数据库中提取规则
-
sql = select * from t1 where b >= 2 and b < 8 and c > 1 and d != 4 and e != ‘a’
-
idx_t1_bcd索引有三个字段,Innodb聚簇索引包含主键a
-
索引按照b字段先排序, b相同按照c排序,依次类推
-
堆表上是乱序的,不按照任何字段排序
-
此SQL覆盖索引idx_t1_bcd上的哪个范围?
- 起始范围:记录[2,2,2],由查询条件b>=2 和c>1决定
- 终⽌止范围:记录[8,8,8],由查询条件b<8决定
-
在确定查询的起始终⽌范围之后, SQL中还有哪些条件可以使用索引 idx_t1_bcd过滤?
- 使⽤用c>1和d != 4进⾏行行索引记录过滤
-
在确定索引中最终能够过滤的条件之后,还有哪些条件是索引⽆法过滤的?
- e字段不在索引中,需要取出表中的e列列,然后使⽤用e列列的查询条件e!=‘a’进⾏行行最终的过滤
-
Where条件在数据库中提取规则-三个关键点
-
Index Key (First Key&Last Key)
- ⽤于确定SQL查询在索引中的连续范围(起始范围+结束范围)的查询条件。
-
Index Filter
- 在完成Index Key提取之后,根据where条件固定索引的查询范围,但是此范围中的项,并不都是满⾜足查询条件的项
-
Table Filter
- 所有不属于索引列的查询条件,均归为Table Filter之中
-
where 查询过程之Index First Key
- 用于确定索引查询的起始范围
- 提取规则:从索引的第⼀键值开始,检查其在where条件中是否存在,若存在并且条件是=、 >=则将对应的条件加入Index First Key之中,继续读取索引的下一个键值
- 若存在并且条件是>,则将对应的条件加入到Index First Key中,同时终止Index First Key的提取
- 例子的Index First Key为(b>=2,c>1),由于c>1,提取结束,不包括d
-
where 查询过程之Index Last Key
- ⽤于确定索引查询的终⽌范围
- 提取规则:从索引的第一键值开始,检查其在where条件中是否存在,若存在并且条件是=、 <=则将对应的条件加⼊入Index Last Key之中,继续读取索引的下⼀个键值
- 若存在并且条件是<,则将对应的条件加⼊入到Index First Key中,同时终止Index Last Key的提取
- 例子的Index Last Key为(b<8),提取结束,不包括c和d
- where 查询过程之Index Filter
- Index Key提取之后,根据where条件固定索引的查询范围之后,但是此范围中的项,并不不都是满⾜足查询的
- 提取规则:从索引第⼀一列列开始,若存在并且where条件仅为=,则跳过继续检查下列列,若为其他,则将where条件中索引相关全部加⼊入到Index Filter之中。(索引的前缀匹配规则)
- 示例:索引第一列只包含>=、 <两个条件,因此第⼀列可跳过,将余下c、 d两列加入Index Filter中。此案例Index Filter为c>1 and d!=4
-
where 查询过程之Table Filter
- 所有不属于索引列查询条件,均归为Table Filter
- 示例例: e != ‘a’ 为Table Filter
-
MySQL-Index Condition PushDown
- MySQL5.6之前,不区分Index Filter 和 Table Filter,在Index Key之后,回表读取完整记录,然后返回给MySQL
- MySQL5.6之后引入ICP,将Index Filter pushdown到索引层面进⾏行过滤
⼀条复杂的SQL加锁分析
-
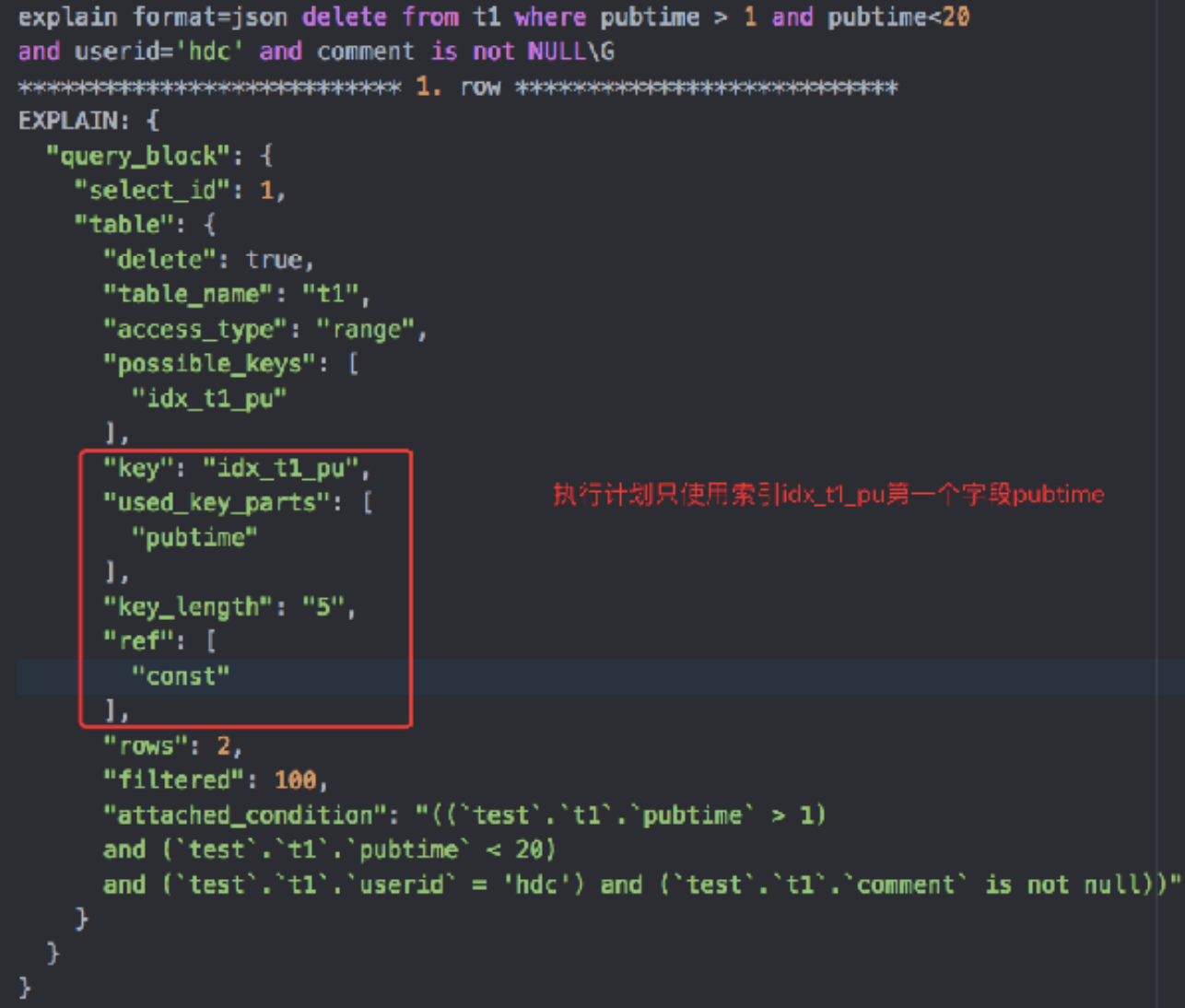
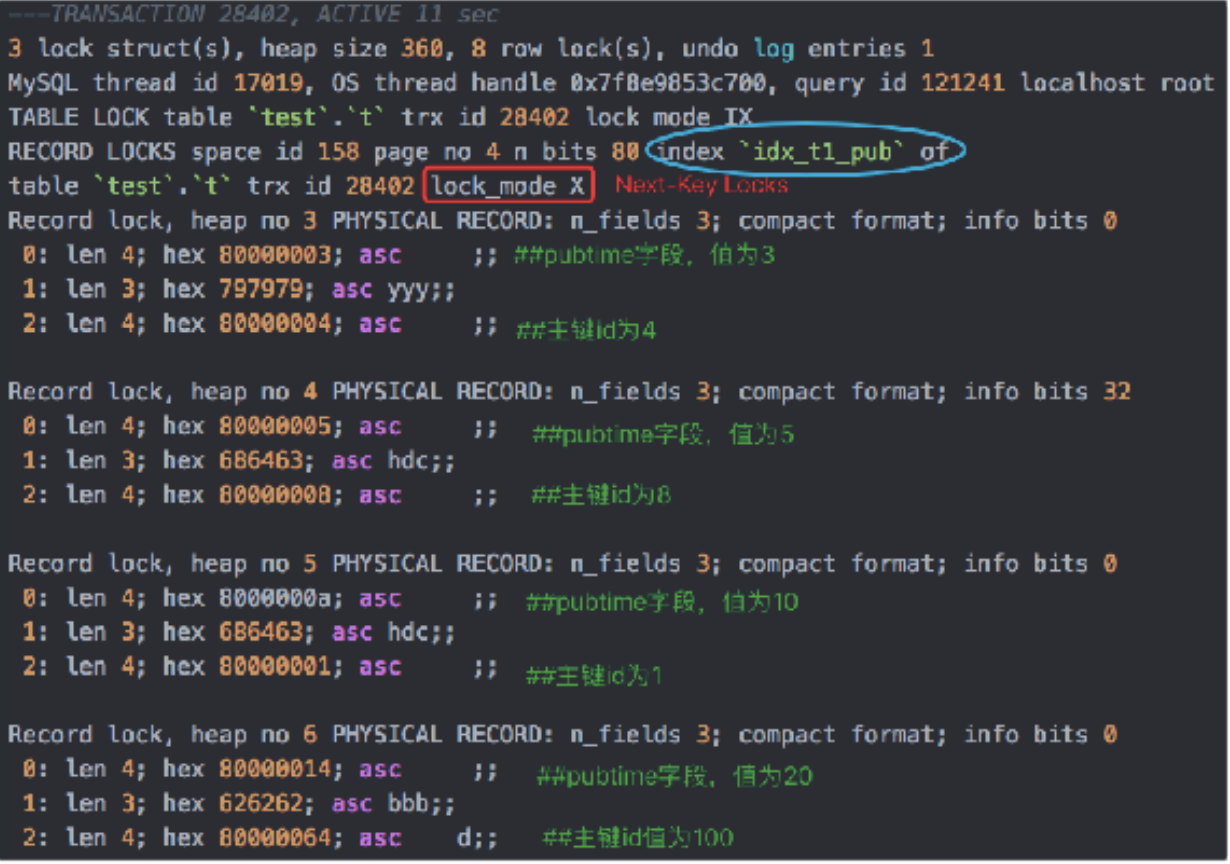
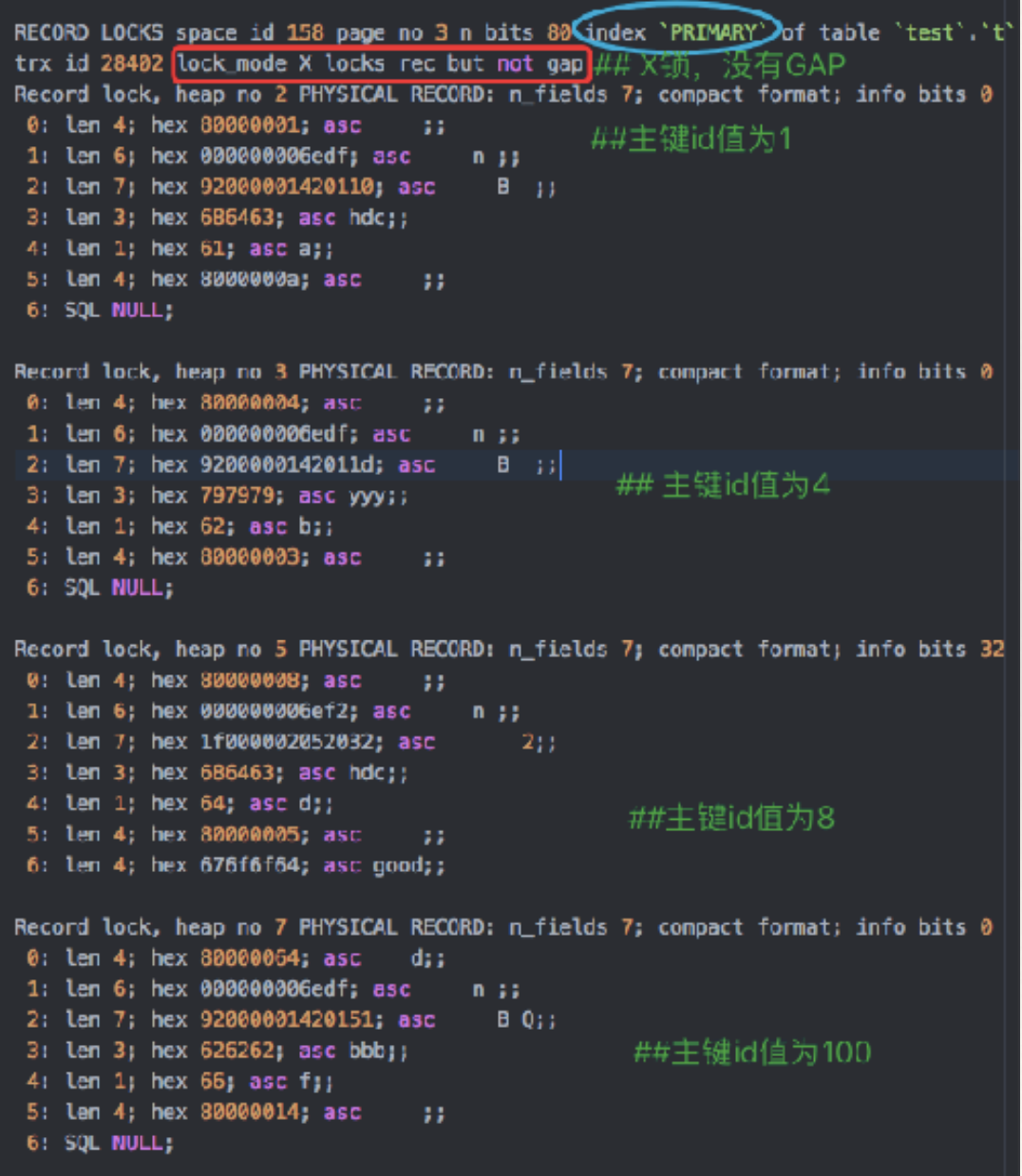
SQL: delete from t1 where pubtime > 1 and pubtime<20 and userid=‘hdc’ and comment is not NULL
-
索引: idx_t1_pu(pubtime, userid)
-
Index Key: pubtime>1 and pubtime<20
-
Index Filter: userid = ‘hdc‘
-
Table Filter: comment is not NULL
-
加锁分析:
- index Key确定的范围加GAP锁:pubtime>1 and pubtime<20,因此加GAP锁
- Index Filter过滤条件看是否⽀支持ICP:userid=‘hdc’,⽀支持ICP话, pubtime=3 不满足filter,不需要加X锁,其聚簇索引对应的id=4也不需要加X锁;否则不支持ICP的话,都加X锁
- Table Filter过滤的条件,无论是否满⾜查询条件,都需要加X锁
InnoDB SQL加锁总结
-
SELECT…FROM
- ⼀致性读不加锁
- 在SERIALIZABLE隔离级别下,对于范围查找加next-key锁,对于唯⼀索引加记录锁
-
SELECT…LOCK IN SHARE MODE
- 加S锁,具体是record lock、 gap lock或者next-key lock,依赖索引情况以及事务隔离级别等
-
SELECT … FOR UPDATE
- 加X锁,具体是record lock、 gap lock或者next-key lock,依赖索引情况以及事务隔离级别等
-
DELETE…WHERE
- 加X锁,具体是record lock还是next-key lock,依赖索引情况以及事务隔离级别等
-
UPDATE…WHERE
- 加X锁,具体是record lock还是next-key lock,依赖索引情况以及事务隔离级别等
- 更新主键的时候,会对影响的⼆级唯⼀索引加上对应的记录S锁和X锁
-
INSERT
- 对插⼊⾏加X锁
- 如果存在唯⼀键冲突,会对这些唯⼀键的记录加S锁
-
INSERT…ON DUPLICATE KEY UPDATE
- 对存在的⾏加next-key Lock
- 对主键重复加X锁
- 对需要更新的数据加X锁
-
REPLACE
- 和INSERT相似,如果有唯⼀键冲突,会对这些唯⼀键的记录加X锁
-
INSERT INTO t SELECT … FROM s WHERE
- 对t中的⾏记录加X记录锁
- 在RC模式下,⼀致性读不加锁 ,在RR模式下,加shared next-key锁
-
AUTO_INCREMENT
- AUTO-INC锁
- 表级锁
-
FOREGIN KEY
- 对涉及的外键记录加S记录锁
-
LOCK TABLES
- 是MySQL server层,⽽不是Innodb引擎层的
- 表锁