- Published on
AWS Aurora Intro
- Authors

- Name
- Guming
介绍
Aurora是一种完全托管的 relational database engine,兼容 MySQL 和 PostgreSQL
Aurora 集群卷可以增长到最大 128 tebibytes (TiB)。Aurora 还自动化和标准化了数据库集群和复制--数据库Ops最具挑战性的方面
Aurora DB clusters
说明
一个 Amazon Aurora DB 集群由一个或多个 DB 实例和一个管理这些 DB 实例数据的集群volume组成
Aurora 集群卷是一个跨多个可用区的虚拟数据库存储卷,每个可用区都包含一个 DB 集群数据的副本
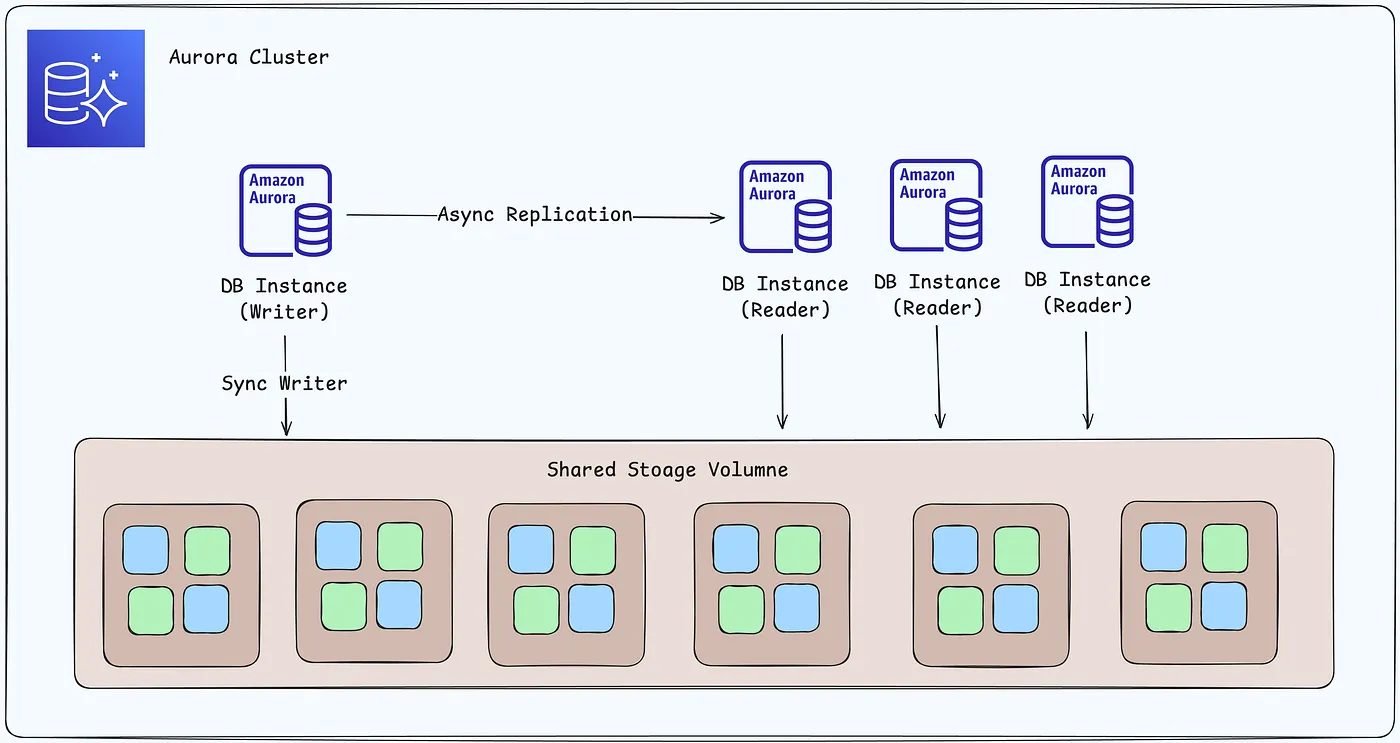
- Primary (writer) DB instance
- 支持读写操作,并对集群卷执行所有数据修改。每个 Aurora 数据库集群有一个主数据库实例
- Aurora Replica (reader DB instance)
- 连接到与主数据库实例相同的存储卷,但仅支持“读取操作”。每个 Aurora 数据库集群除了主数据库实例外,最多可以有 15 个 Aurora 复制
下列图表说明了 Aurora 数据库集群中的集群卷、写入数据库实例和读取数据库实例之间的关系
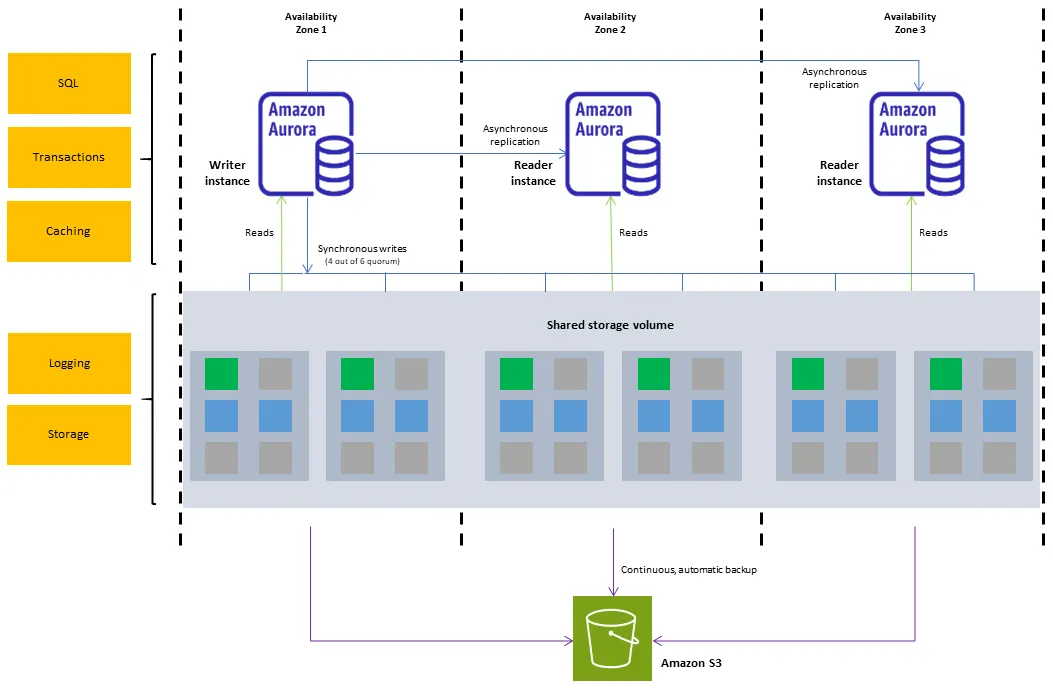
Aurora DB cluster 是存储与计算分离架构
一个仅包含单个数据库实例的 Aurora 配置仍然是一个集群,因为底层的存储涉及多个存储节点,这些节点分布在多个可用区(AZ)
Aurora endpoint connections
Aurora 通常涉及一个由多个 DB 实例组成的集群,而不是单个实例。每个连接都由特定的 DB 实例处理。当你连接到 Aurora 集群时,你指定的主机名和端口指向一个称为端点的中间处理程序。Aurora 使用端点机制来抽象这些连接。因此,你不必硬编码所有主机名,也不需要编写自己的逻辑来平衡和重定向连接,当某些 DB 实例不可用时
Types of Aurora endpoints
- Cluster endpoint 执行 DDL DML等语句,您可以连接到主实例
- Reader endpoint 要执行查询,您可以连接到“读取端点”,Aurora 将自动在所有 Aurora 副本之间进行连接均衡
- Custom endpoint 对于具有不同容量或配置的 DB 实例的集群,可以连接到与不同 DB 实例子集关联的自定义端点
- Instance endpoint 在进行诊断或调优时,可以通过连接到特定的实例端点来检查特定数据库实例的详细信息
- Aurora Global Database writer endpoint 跨区域部署的 Aurora 集群endpoint,提供跨区域的Switchover
ps. endpoint表示为一个包含主机地址和端口号的 Aurora 特定 URL
Aurora DB instance classes
数据库实例类别包括:
- DB instance class type 数据库实例类型
- DB Instance size 数据库实例大小
db.r6g”是一种由 AWS Graviton2 处理器支持的内存优化数据库实例类型。在 db.r6g 实例类型中,“db.r6g.2xlarge”是一种数据库实例类型,该类型的大小为 2xlarge。
Aurora storage
Aurora 将数据存储在一个单一的、虚拟的 SSD 支持的卷中,该卷在“一个 AWS 区域”内的“三个可用区”中复制。这种自动复制增强了持久性,降低了数据丢失的风险,并在故障转移期间确保可用性,因为数据副本始终可访问,无论数据库实例的数量是多少。
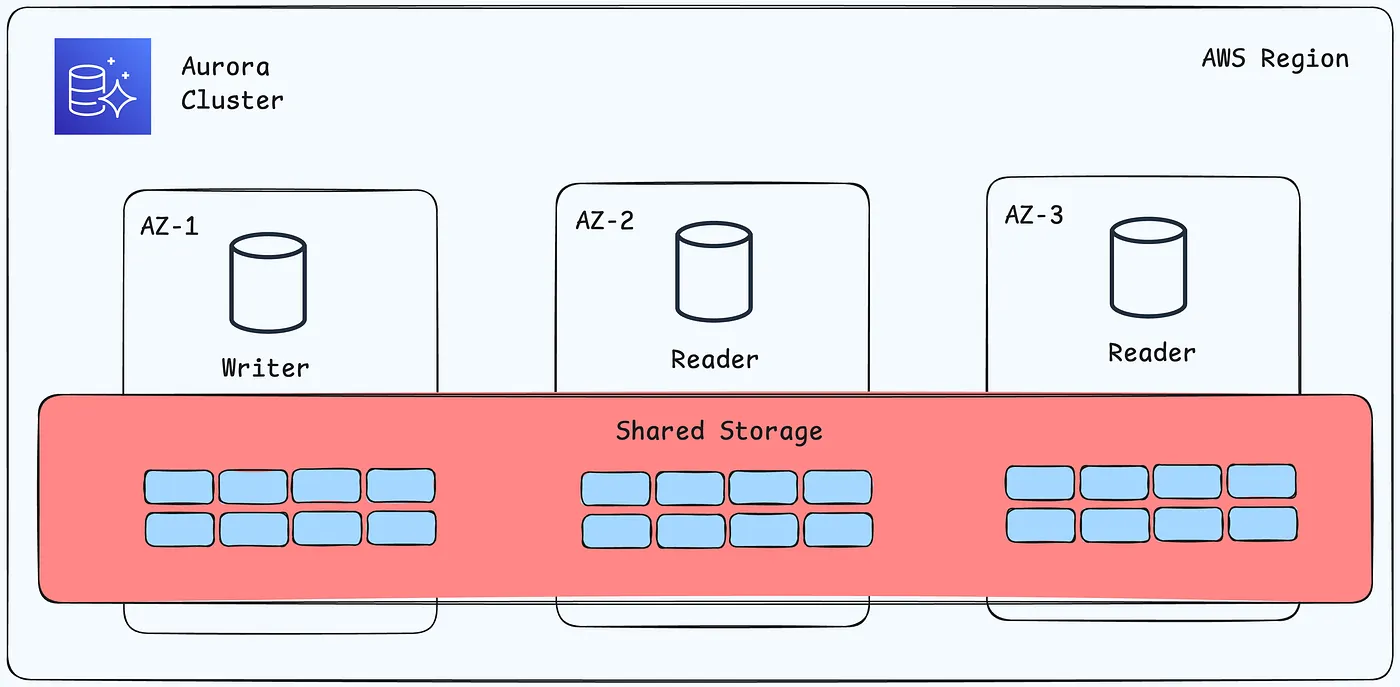
Aurora cluster volume 包含所有的“用户数据、schema对象和内部元数据”,例如系统表和二进制日志
Aurora 共享存储架构使您的数据独立于集群中的 DB 实例(计算与存储分离),可以快速添加一个 DB 实例, Aurora 不会复制新的表数据。相反,DB 实例连接到已经包含所有数据的共享卷。可以从集群中删除一个 DB 实例,而无需从集群中删除任何底层数据。只有当删除整个集群时,Aurora 才会删除数据
Aurora storage配置
- Aurora I/O-Optimized(*) — 最适合高 I/O 工作负载(其中 I/O 成本占 Aurora 总支出的 25% 或更多),只需为存储和使用付费,读写操作无需额外费用。可以随时切换回 Aurora Standard
- Aurora Standard — 适用于中等 I/O 工作负载(I/O 成本占总支出的 25% 以下
ps.删除 Aurora 数据时,例如通过删除表或数据库,整体分配的空间会相应减少。因此,可以通过删除不再需要的表、索引、数据库等来降低存储费用
另,需要注意 这两者选项之间切换对非 NVMe 实例是无缝的。然而,对于基于 NVMe 的实例,切换需要重启,会导致短暂停机 ** NVMe = SSD 专用的高速通道协议,它利用 PCIe (Peripheral Component Interconnect Express) 通道来直接和 CPU 通信,不再经过传统的磁盘控制器,因此延迟极低、吞吐量极高
Aurora Reliability
通过添加 Aurora 副本并将它们放置在不同的可用区来构建您的 Aurora 数据库集群以提高可用性,此外 Aurora 还包括几个自动功能,使其成为一个可靠的数据库解决方案
Storage auto-repair
- Aurora 会自动检测构成集群卷的磁盘卷的故障。当磁盘卷的一部分发生故障时,Aurora 会立即修复该部分。当 Aurora 修复磁盘段时,它使用构成集群卷的其他卷中的数据来确保修复段中的数据是最新的。因此,Aurora 避免数据丢失,并减少从磁盘故障中恢复时执行时间点还原的需求

Survivable page cache
- 在 Aurora 中,每个数据库实例的页面缓存由独立于数据库的进程管理,这使得页面缓存能够在数据库独立生存
- 在 Aurora MySQL 中,页面缓存也称为 InnoDB 缓冲池
- 在 Aurora PostgreSQL 中称为缓冲缓存
- 数据库故障情况下,页面缓存仍然保留在内存中,当数据库重新启动时,这使当前数据页面在页面缓存中保持“热”状态。这通过绕过初始查询执行读取 I/O 操作以“预热”页面缓存的必要性,从而提供了性能提升
- 对于 Aurora PostgreSQL,可以使用集群缓存管理来保留在故障转移后成为写入实例的指定读取实例的页面缓存
- 在 Aurora 中,每个数据库实例的页面缓存由独立于数据库的进程管理,这使得页面缓存能够在数据库独立生存
Aurora High Availability
High Availability for “Aurora Data”
- Aurora 将数据副本存储在单个 AWS 区域内跨多个可用区的数据库集群中。无论数据库集群中的实例是否跨越多个可用区,Aurora 都会存储这些副本
- 当数据写入主数据库实例时,Aurora 会“同步地”将数据复制到与您的集群卷关联的六个存储节点,跨多个可用区
- 这样做提供了数据冗余,消除了 I/O 停顿,并在系统备份期间最小化延迟峰值。运行具有高可用性的数据库实例可以在计划系统维护期间提高可用性,并帮助保护您的数据库免受故障和可用区中断的影响
High Availability for “Aurora DB instances”
- 创建主(写入)实例后,您可以创建最多 15 个只读 Aurora 复制实例。Aurora 复制实例也称为读取实例。Aurora 复制实例使用“异步复制”来支持高可用性,而不会影响主实例的性能
- 当主库出现问题时 Aurora Failover To Reader Replica
- 使用cluster endpoint 即使在故障转移时提升新主实例后仍保持不变的连接字符串
Aurora Global Databases for cross regions
- 要在多个 AWS 区域中实现高可用性,您可以设置 Aurora 全局数据库。每个 Aurora 全局数据库跨越多个 AWS 区域,支持低延迟的全球读取以及跨 AWS 区域故障的灾难恢复。Aurora 将主 AWS 区域的所有数据和更新异步复制到每个次级区域
- switchover

- Switchover 会等待两个 Region 的 write lsn 完全对齐以后, 再进行切换. 从而保证 RPO = 0. 同时也保证 standby region 的资源和 primary region 对齐, 从而不影响切换过来的性能
- 仍保留failover能力

- Aurora 跨 region 切换 RTO = 1~2 minutes. 切换过去以后, Region A 会重新和 Region B 建立主备关系, Region B 成为主 region, region A 成为 standby region. 并且这里 Region A 会在 crash 那个时刻打一个快照, 从而方便用户查询数据
概括下集群的容错性
- Data Durability
- Multi-AZ Storage 👆已有描述
- Instance Availability 👆已有描述
- Automatic Failover
- Primary and Replicas 主备切换
- Global Resilience - Aurora Global Databases 👆已有描述
- Fault Tolerance Features:
- Storage Auto-Repair 👆已有描述
- Survivable Cache 👆已有描述
管理 Amazon Aurora DB 集群
手动向数据库集群添加 Aurora 副本 -15个上限
Auto Scaling with Aurora Replicas
- 为 Aurora 数据库集群定义并应用一个扩展策略
- 扩展策略定义了 Aurora 自动扩展可以管理的 Aurora 副本的最小和最大数量

- target-tracking scaling policy
- 使用预定义的平均“CPU 利用率指标”的扩展策略。此类策略可以将 CPU 利用率保持在或接近指定的利用率百分比,例如 40%
- 可以跟着endpoint 指定,不同的endpoint指定不同的metrics
- Cooldown period
- 冷却期会阻止后续的扩展或缩减请求,直到冷却期结束
- 如果你没有设置scale-in或scale-out的冷却时间,每个的默认值是 300 秒
- 为 Aurora 数据库集群定义并应用一个扩展策略
Aurora DB 集群克隆卷
- 通过使用 Aurora 克隆功能,创建一个新的集群,该集群最初与原始集群共享相同的数据页,但确是一个独立的卷
- 与使用其他技术(如snapshot)物理复制数据相比,创建克隆更快且更节省空间
- copy-on-write protocol
- Aurora 克隆特别适用于使用生产数据快速设置测试环境,而不会导致数据损坏
- 可以从同一个 Aurora DB 集群创建多个克隆。也可以从另一个克隆创建多个克隆
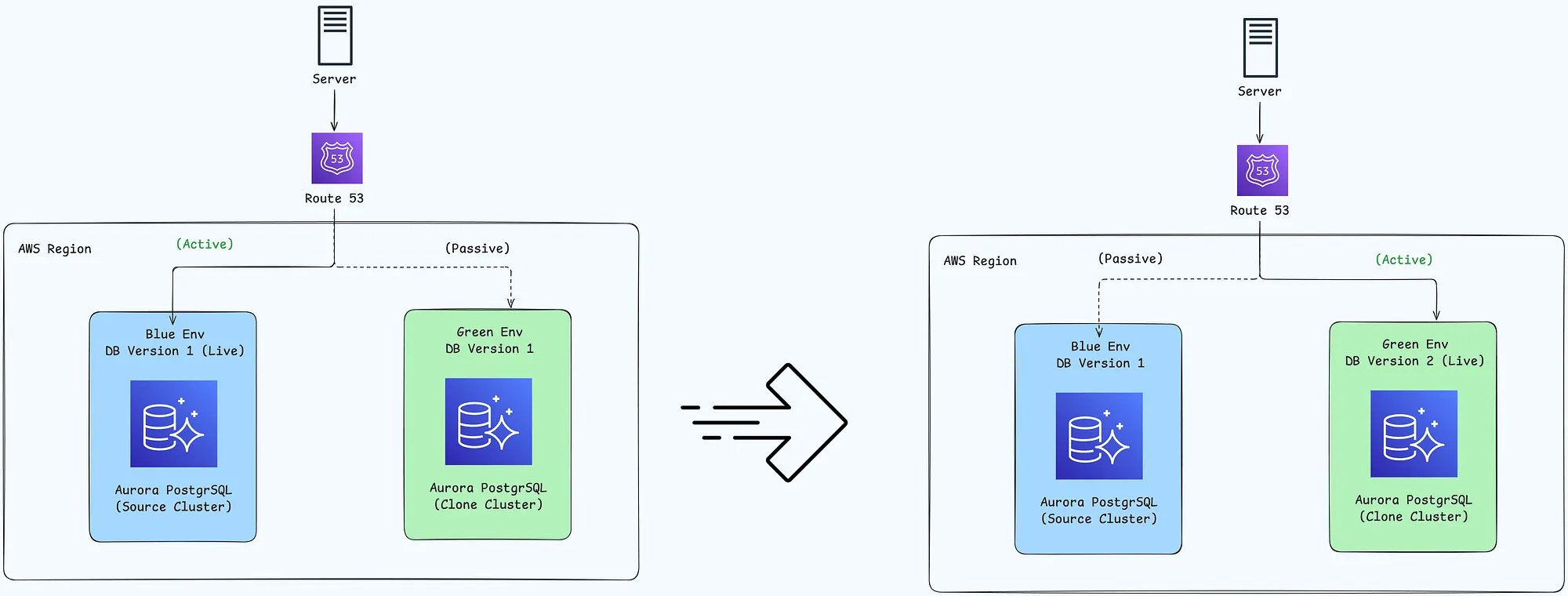
Aurora Blue/Green Deployments for database updates
- Backing up and restoring data
Aurora 自动备份您的集群卷(S3),并在备份保留期内保留恢复的数据。Aurora 自动备份是连续和增量式的,因此可以在备份保留期内快速恢复到任何时间点
在创建或修改数据库集群时,您可以指定 1 至 35 天的备份保留期。Aurora 自动备份存储在 Amazon S3 中
亦可以使用 AWS Backup 手动/自动备份,可以自定义backup窗口
ps.删除一个 Aurora 托管的或 Aurora Serverless v2 数据库集群时,可以选择保留自动备份。这意味着即使删除后,仍然可以在备份保留期内将数据库恢复到特定的时间点
保留期结束,自动备份会永久消失
手动快照不会过期,所以在删除集群之前拍一个最终的快照是个好主意,即使保留了自动备份
Amazon RDS 在以下几种情况下会删除自动备份:
- 在其保留期结束时
- 当你禁用某个数据库集群的自动备份时
- 当你删除某个数据库集群时
如果想将自动备份保留更长时间,可以将其复制以创建手动快照,该快照将保留
Monitoring metrics
监控关键性能指标:
- CPU 和 RAM 使用率:高使用率可能因您的负载而正常,但应与预期性能一致。
- 磁盘空间:调查使用率是否持续超过总容量的 85%。
- 网络流量:确保吞吐量达到预期水平;显著偏差需要调查。
- 数据库连接:过多的连接会降低性能;考虑通过参数组设置限制。
- 每秒输入/输出操作数(IOPS):将当前 IOPS 与基线进行比较以检测异常。
工具:
- Database Insights performance排查
- Anomaly Detection: DevOps Guru for RDS RDS DevOps Guru 识别异常行为,例如 CPU 突然飙升,并提供反应性洞察和推荐
- CloudWatch console Aurora 提供了详细的 CloudWatch 指标,包括 CPU 利用率、磁盘 I/O 和网络吞吐量
- Enhanced Monitoring 提供“实时”操作系统(OS)指标,包括 CPU、内存、文件系统使用情况和磁盘 I/O。启用此功能时,它还提供详细的进程级洞察,而无需重新启动
Monitoring Aurora events
Amazon RDS 记录与以下资源相关的事件:
- DB clusters 数据库集群
- DB instances 数据库实例
- DB parameter groups 数据库参数组
- DB security groups 数据库安全组
- DB cluster snapshots 数据库集群快照
- RDS Proxy events RDS 代理事件
- Blue/green deployment events 蓝绿部署事件
Monitoring Amazon Aurora log files
可以使用 AWS 管理控制台、AWS 命令行界面 (AWS CLI) 或 Amazon RDS API 访问数据库实例的数据库日志
Monitoring Amazon Aurora with Database Activity Streams
Aurora 的数据库活动流 (DAS) 提供近乎实时的数据库活动流,允许您监控和审计数据库中的 SQL 级别操作。此功能通过记录和流式传输数据库事件,帮助检测未经授权的访问、异常行为和合规性违规
Asynchronous Mode(可能有丢失)/Synchronous Mode(性能有影响)
Aurora PostgreSQL Limitless Database
目标适配Database scaling场景
Limitless Database 提供自动“水平扩展”功能,以每秒处理数百万次写入事务,同时管理 PB 级数据,同时保持在单个数据库内操作的简便性
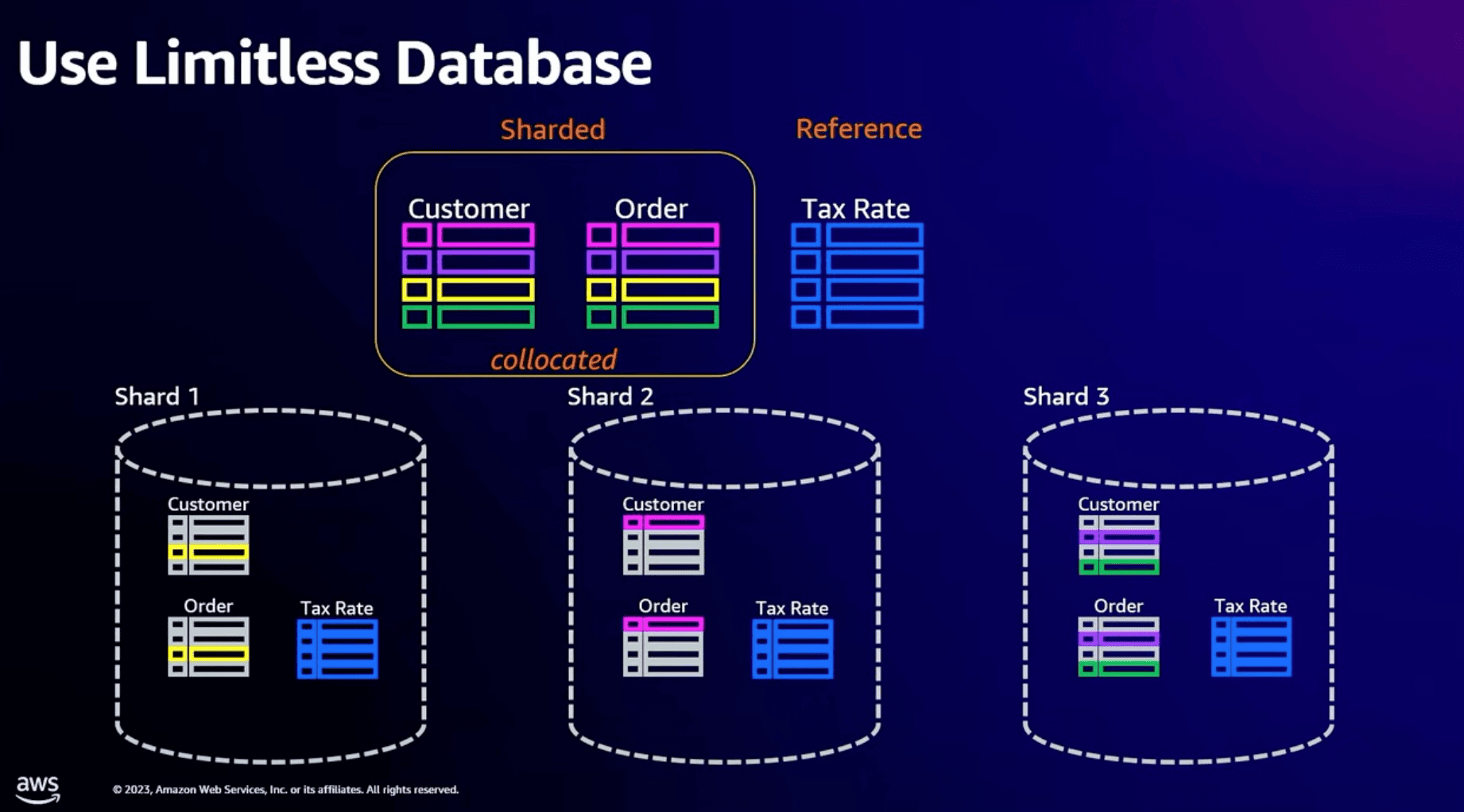
Types of Table
- Shared table : 从下图可以看到 Shared table 将一个 table partitioned 到多个 Shared 上.
CREATE TABLE Users (
user_id SERIAL PRIMARY KEY,
name TEXT,
email TEXT UNIQUE,
country_id INT
) DISTRIBUTE BY HASH (country_id);
- Reference table: 将一份数据 Copy 到多个 Shared 中, 每一个 Shared 都有完整的数据, 主要解决的场景是在 Join 等场景中, 可以做到 Local Join 从而优化性能
CREATE TABLE Countries (
country_id SERIAL PRIMARY KEY,
country_name TEXT
) DISTRIBUTE REPLICATE;
- Collocated Tables: 是一种特殊的Sharded Table 其中两个或多个表共享相同的分片键。这确保了相关数据始终存储在同一个分片中,从而大大加快了它们之间的连接速度
CREATE TABLE Orders (
order_id SERIAL PRIMARY KEY,
customer_id INT,
order_date TIMESTAMP DEFAULT NOW()
) DISTRIBUTE BY HASH (customer_id);
CREATE TABLE OrderItems (
item_id SERIAL PRIMARY KEY,
order_id INT,
product_id INT,
customer_id INT,
quantity INT
) DISTRIBUTE BY HASH (customer_id);
- Standard Tables : 存储在单个分片上,系统会自动选择一个单独的分片来存储此表
例如,一个用于跟踪用户活动的 Logs 表可以存储为标准表,因为它通常作为整体进行查询,与其他标准表进行连接是高效的,因为所有数据都在同一个分片上
CREATE TABLE Logs (
log_id SERIAL PRIMARY KEY,
user_id INT,
action TEXT,
timestamp TIMESTAMP DEFAULT NOW()
);
Limit
- 每个集群仅支持一个分片组:每个 DB 集群仅支持一个分片组,每个 AWS 区域最多允许五个分片组
- 固定数量的路由器和分片:分片组的初始路由器和分片数量由创建分片组时设置的容量上限决定
- 不可变的分片键
- 隔离级别:支持的隔离级别包括可重复读、已提交读和未提交读。不支持可序列化隔离级别
Splitting Shards
user-based/system-based Split Action
启用系统触发的分片拆分: rds_aurora.limitless_enable_auto_scale :设置为 on 以允许自动扩展。 rds_aurora.limitless_auto_scale_options :包含 split_shard 以允许自动分片拆分。
监控分片拆分状态很简单, 可以查询 rds_aurora.limitless_list_shard_scale_jobs 函数来跟踪正在进行的或已完成的分片拆分操作
Router
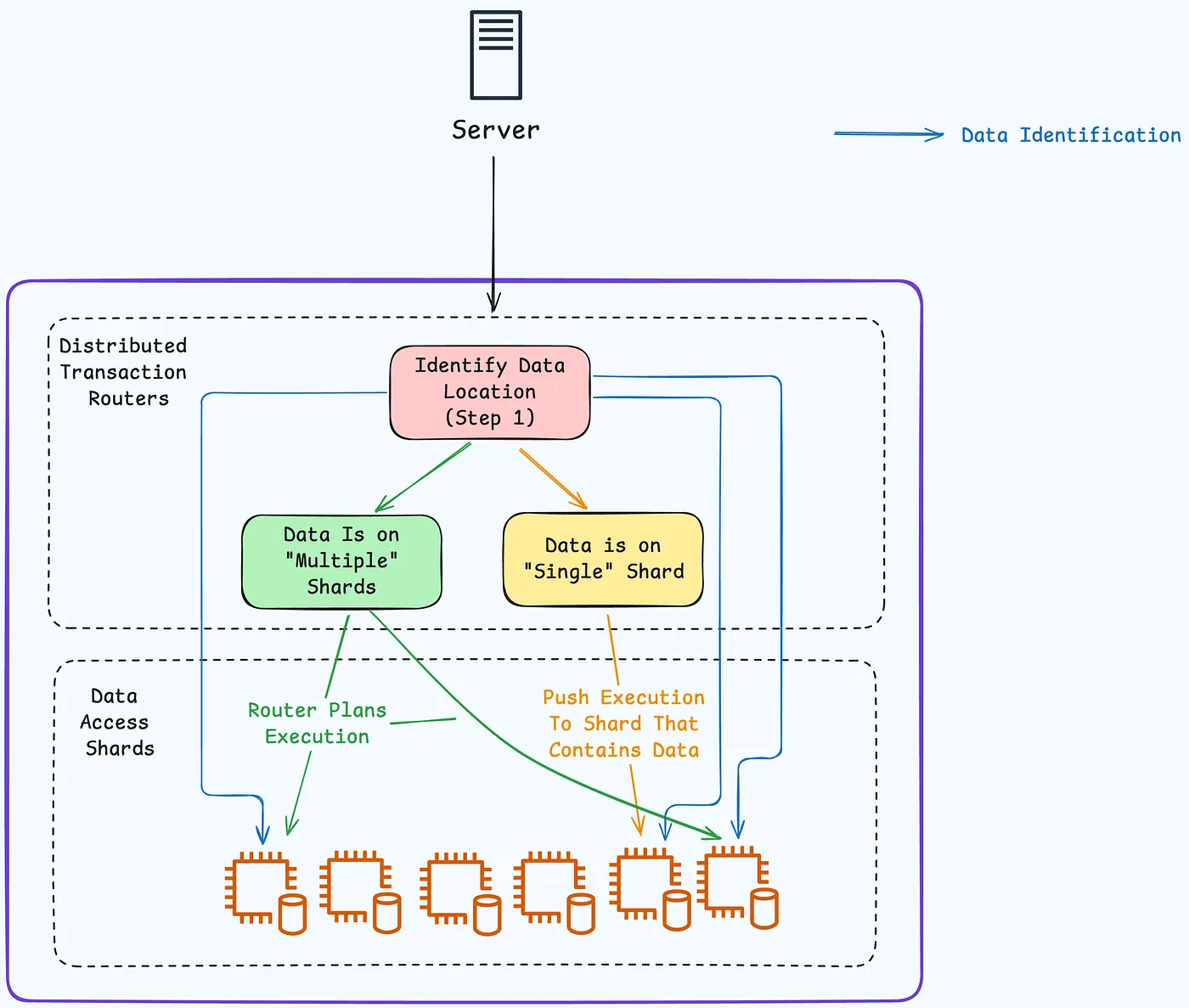
将客户端请求引导至相应的分片, 添加更多路由器可以增强系统处理大量并发连接的能力,从而提高整体性能
- 如果数据分布在多个分片中,路由器会跨它们规划查询执行
- 如果所有数据都在单个分片上(基于分片键)或位于参考表中,路由器会跳过查询规划
执行此操作的用户必须拥有 rds_aurora_limitless_cluster_admin 权限。
使用函数 rds_aurora.limitless_add_router() 来启动添加新路由器的操作
使用rds_aurora.limitless_list_router_scale_jobs 函数来监控路由器添加的进度
查询优化
- Optimized Reads - Temporary objects

- Tiered Cache 能力, 通过本地盘对Aurora storage 进行读加速
 Tiered cache 流程是在 buffer pool 里面保留了一份tiered cache 的 MetaData, 读取的时候先检查 MetaData 里面有没有, 如果有直接从本地盘读取, 如果没有从 Aurora storage 读取.
Tiered cache 流程是在 buffer pool 里面保留了一份tiered cache 的 MetaData, 读取的时候先检查 MetaData 里面有没有, 如果有直接从本地盘读取, 如果没有从 Aurora storage 读取.
那么什么时候往 tiered cache 里面写入内容呢?
和 external bufferpool 一样, 等这个 page 被 LRU list淘汰的时候(Page 不能是脏页), 并不是直接从内存中删除, 而是加入到 tiered cache 里面, 这里具体实现的时候要考虑 LRU list mutex 的开销了.
在读取的路径并不会主动去更新 tiered cache, 从而保证了读取性能.
Update 的时候也只需要更新 tiered cache 的 MetaData, 表示 tiered cache 里面的 page 是无用的就可以. 下次读取的时候, 就不会读取 tiered cache 里面的 Page.
那么 tiered cache 里面的内容如果做 LRU list 的淘汰呢? Aurora 选择的测试是随机淘汰
这一部分无需用户干预
- 由于shard带来的问题,建议Explicit Join Condition
customer_id 是shard-key
SELECT * FROM
customers c, orders o, order_details od
WHERE c.customer_id = o.customer_id
AND o.customer_id = od.customer_id -- ✅ Added explicit join condition
AND od.order_id = o.order_id
AND c.customer_id = 1;
- Setting an Active Shard Key
活动分片键会将会话中的所有后续查询定向到特定的分片。这在执行针对同一分片的多项操作时特别有用,因为它最大限度地减少了确定每个查询的分片的开销
SET rds_aurora.active_shard_key = 'your_shard_key_value';
Resolve distributed deadlocks automatically
Aurora PostgreSQL 无限数据库可以自动检测和解决分布式死锁。当事务等待过长时间以获取资源时,DB 分片组中的路由器会收到通知。收到通知的路由器开始从 DB 分片组中的所有路由器和分片中收集必要信息。然后,路由器会结束参与分布式死锁的事务,直到 DB 分片组中的其余事务可以相互不被阻塞地继续进行
ERROR: aborting transaction participating in a distributed deadlock
rds_aurora.limitless_distributed_deadlock_timeout 数据库集群参数设置了每个事务在通知路由器检查分布式死锁之前等待资源的时间。如果业务不太容易发生死锁情况,您可以增加参数值。默认值为 1000 毫秒
Aurora limitless 定位
大数据量,有shard需求,且用户明确shard key的场景
如果是少量数据且iops不高,无需使用此产品
Aurora 全局数据库
一个 Aurora 全球数据库在一个区域拥有一个主 DB 集群,并在不同区域拥有多达五个辅助 DB 集群
使用场景
多区域配置可以在罕见的影响整个 AWS 区域的停机事件中提供快速恢复。在多个地理位置存储所有数据的完整副本,也能为连接到世界各地相距较远位置的应用程序提供低延迟的读取操作
Advantages of Amazon Aurora Global Database
- 具有本地延迟的全局读取
- 可扩展的 Aurora 二级数据库集群 — 可以通过向二级 AWS 区域添加更多只读实例来扩展二级集群。二级集群是只读的,因此它可以支持高达 16 个只读 DB 实例,而不是单个 Aurora 集群通常的 15 个限制
- 从主 Aurora DB 集群到二级 Aurora DB 集群的高速复制 — Aurora Global Database 执行的复制对主 DB 集群的影响很小。DB 实例的资源完全用于服务应用程序读写工作负载
- 从区域级停机中恢复 — 二级集群允许您更快地(较低的 RTO)并在更少的数据丢失(较低的 RPO)的情况下,在新的主 AWS 区域中使 Aurora Global Database 可用,而不是传统的复制解决方案
Limitations
- 某些 Aurora 功能与 Global Database 不兼容。例如,Backtrack 功能,它允许将数据库集群回滚到先前的某个时间点,在此配置中不受支持
- 区域和集群约束:Aurora Global Database 支持一个用于写入操作的主 AWS 区域,以及最多五个只读的次要区域。每个次要区域都托管自己的 Aurora DB 集群,但 Global Database 中的所有集群都必须位于不同的 AWS 区域
- 从主区域到次要区域的复制是异步的。这意味着在数据写入主集群和它在次要集群中可用之间存在轻微的延迟
Configuration requirements
Aurora 全局数据库至少跨越两个 AWS 区域。主要 AWS 区域支持一个 Aurora DB 集群,该集群包含一个写入型 Aurora DB 实例。次要 AWS 区域运行一个完全由 Aurora 复制实例组成的只读 Aurora DB 集群
- AWS 区域分布:Aurora 全局数据库必须在其中一个 AWS 区域中有一个主 DB 集群,并在不同区域中至少有一个次要(只读)DB 集群
- 实例类别:应使用针对内存密集型应用优化的 DB 实例类别。建议使用 db.r5 或更高实例类别
- 全局数据库中的每个 Aurora DB 集群必须在所有 AWS 区域中具有唯一名称。即使在不同区域中,重复名称也不允许(有点像s3)
- Aurora Serverless v2 容量:对于使用 Aurora Serverless v2 的配置,主 AWS 区域中 DB 集群的最低推荐容量为 8 个 Aurora 容量单位(ACUs)
Headless Aurora DB cluster in a secondary Region
当您向全局数据库添加一个次要集群时,AWS 会自动在该次要区域创建一个读取实例。然而,在headless设置中,会删除这个读取实例,只保留存储层处于活动状态
No direct query access
何时使用headless集群?
要全局复制用于灾难恢复,但不需要一直保持活动读副本
需要最小化成本,但仍然希望在主集群失败时有一个快速恢复选项
connection endpoint
writer endpoint : primary cluster
reader endpoint : reader in primary cluster/secondary clusters
Global writer endpoint: cross region to the writer instance
write forwarding :Forward write request from secondary clusters to writer in the primary cluster
切换/故障转移 switchover or failover
RTO 衡量停机时间, 对于 Aurora Global Database,RTO 可能在分钟级别
RPO 衡量数据丢失,RPO 通常以秒为单位。使用基于 Aurora PostgreSQL 的全局数据库,您可以使用 rds.global_db_rpo 参数来设置和跟踪 RPO 的上限,但这可能会影响主集群写入节点的交易处理
Failover 将执行跨区域的故障转移到 Aurora 全局数据库中的某个辅助 DB 集群,对于这种方法,“RPO”通常是秒为单位的非零值。数据丢失量取决于故障发生时 Aurora 全局数据库在 AWS 区域之间的复制延迟
switchover 适用于业务是全球的, 白天时候是高峰期, 所以一直切换保证就近的 Region 读取的性能是最好的. 因为没有集群故障 RPO近于0
Aurora Serverless v2
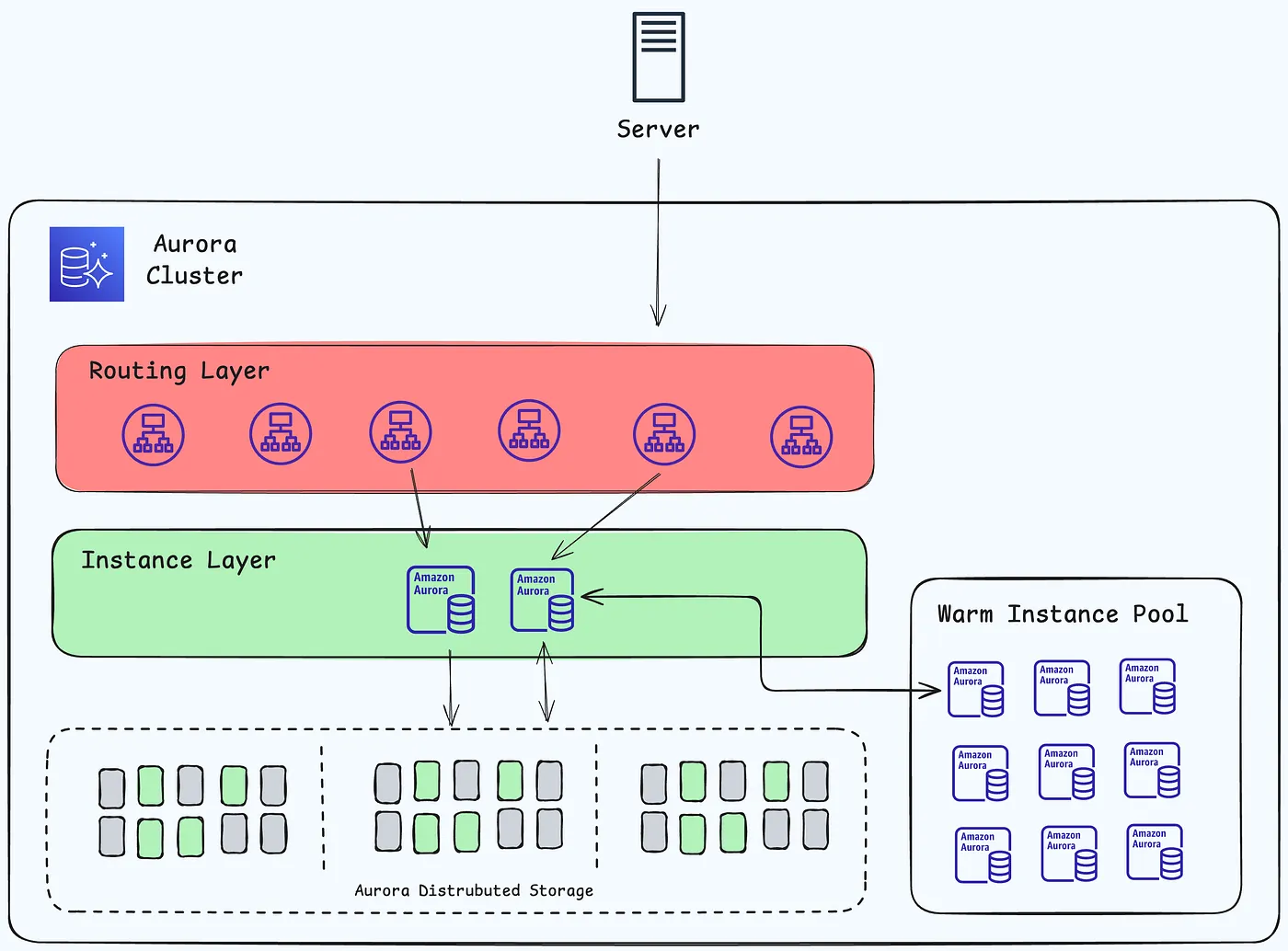
Aurora Serverless v2 是 Amazon Aurora 的按需自动扩展配置
Aurora Serverless v2 帮助自动化监控工作负载和调整数据库容量
容量会根据应用程序需求自动调整。只需为数据库集群消耗的资源付费
Aurora Serverless v2 High-Level Architecture
Aurora Serverless v2 use cases
- 可变工作负载:对于经历突发且不可预测流量高峰的应用程序,例如促销期间的电子商务网站,Aurora 无服务器 v2 动态扩展容量以满足峰值需求,并在需求回落后再进行缩减
- 多租户应用程序:在多个租户共享数据库资源的情况下,Aurora 无服务器 v2 自动管理单个数据库容量,允许每个租户的集群根据其特定的活动水平进行扩展。
- 在启动具有不确定数据库大小需求的新应用程序时,Aurora 无服务器 v2 通过自动扩展来匹配应用程序不断变化的能力需求
- 混合用途应用程序:对于主要处理事务性操作但偶尔面临读流量波峰的应用程序,Aurora Serverless v2 允许读取实例独立扩展,确保高效处理波动的工作负载
Advantages of Aurora Serverless v2
- Aurora Serverless v2 以细粒度调整容量,根据工作负载需求增减,最少可调整 0.5 Aurora 容量单位(ACU)。这种精确扩展确保资源与应用程序需求紧密匹配
- Cost Efficiency 通过在低活动期间自动缩减规模,Aurora Serverless v2 有助于最小化成本,确保您只需为实际使用的容量付费
- 自动扩展和容量管理减少了与手动数据库扩展相关的运维负担,使开发人员能够更专注于应用程序开发
Disadvantages of Aurora Serverless v2
- 需要注意成本,由于底层维持 warm capacity,很可能比 provisioned 实例更贵
- Aurora Serverless v2 按 ACU(Aurora Capacity Unit) 实时自动扩缩容,但扩缩容的触发点不透明,可能造成账单波动
- 连接池需要重新设计:对于长连接型应用(如 Java、.NET),传统连接池(HikariCP 等)无法直接感知 Aurora 的自动扩缩容行为
Limitations
- 适合不稳定或间歇性流量 如 SaaS 多租户系统后台、内部分析平台
对于持续高负载、低延迟的核心数据库,provisioned Aurora 通常更可控、更便宜
Configurations for Aurora DB clusters
Provisioned Capacity
Aurora Serverless v2 (Fully Auto-Scaling)
每个 ACU 包含大约 2 gibibytes(GiB)的内存、相应的 CPU 和网络。使用此计量单位指定数据库容量范围。 ServerlessDatabaseCapacity 和 ACUUtilization 指标帮助您确定数据库实际使用的容量以及该容量在指定范围内的位置
Mixed-Configuration Clusters (Best of Both Worlds)
- 写入操作需要高且可预测的性能,但读取工作负载会变化。可以使用预留的写入器与 Serverless v2 读取器。
- 读取流量稳定,但写入量会波动。在这种情况下,可以使用 Serverless v2 写入器与预留的读取器
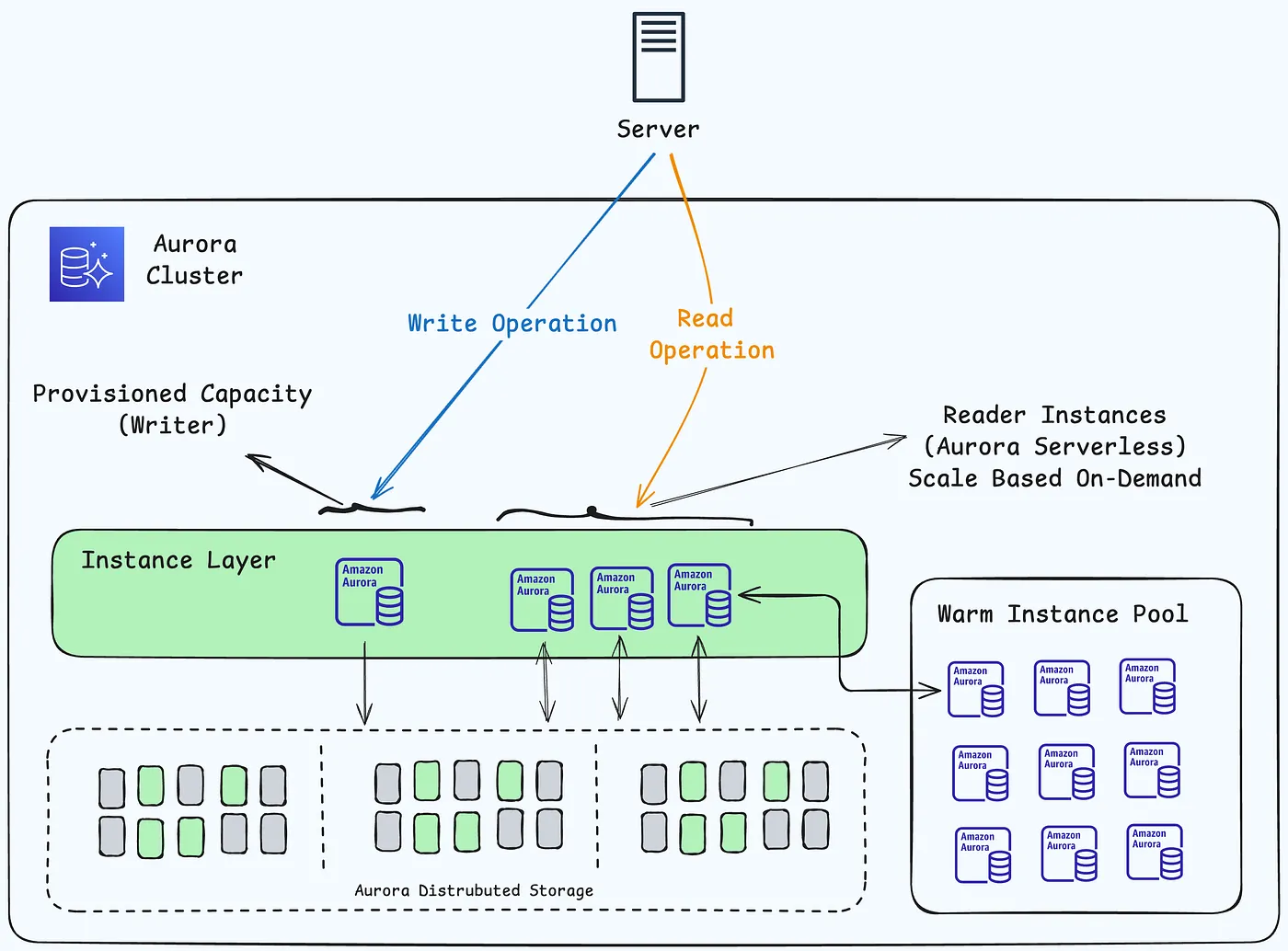
Aurora Serverless v2 scaling
每个 Aurora Serverless v2 写入器或读取器,Aurora 会持续跟踪 CPU、内存和网络等资源的利用率
当 Aurora Serverless v2 检测到可以通过自动扩展解决的问题的性能问题时,它也会自动扩展
scaling 是增加或减少 Aurora Serverless v2 数据库容量的操作。使用 Aurora Serverless v2,每个写入者和读取者都有自己的当前容量值,以 ACU(计算单元)衡量。当写入者或读取者的当前容量不足以处理负载时,Aurora Serverless v2 会将其扩展到更高的容量。当写入者或读取者的当前容量高于所需时,它会将其扩展到更低的容量。
Aurora Serverless v2 可以增量式地增加容量。当负载开始达到写入者或读取者的当前数据库容量时,Aurora Serverless v2 会为该写入者或读取者增加 ACU 数量。Aurora Serverless v2 以提供最佳性能所需的资源消耗为增量来扩展容量。扩展以最小的 0.5 ACU 增量为单位进行。当前容量越大,扩展增量就越大,因此扩展速度就越快
Amazon RDS Proxy for Aurora
Amazon Aurora 的 RDS Proxy 通过池化和共享数据库连接来提高可扩展性和弹性。它在故障期间自动连接到备用实例,执行 IAM 身份验证,并将凭证安全地存储在 AWS Secrets Manager 中
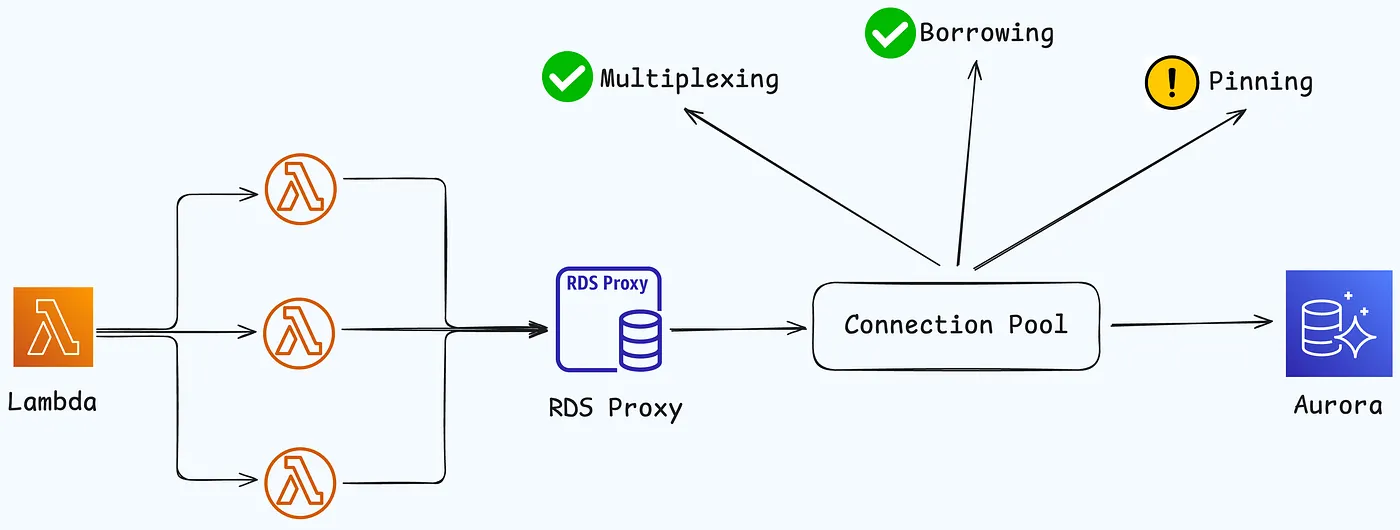
Connection pooling
Failover
通过Proxy连接可以使应用程序在数据库故障转移时更具弹性。当原始数据库实例不可用时,RDS 代理会连接到备用数据库,而不会中断空闲的应用程序连接。这有助于加快并简化故障转移过程。与典型的重启或数据库问题相比,这对应用程序的干扰更小
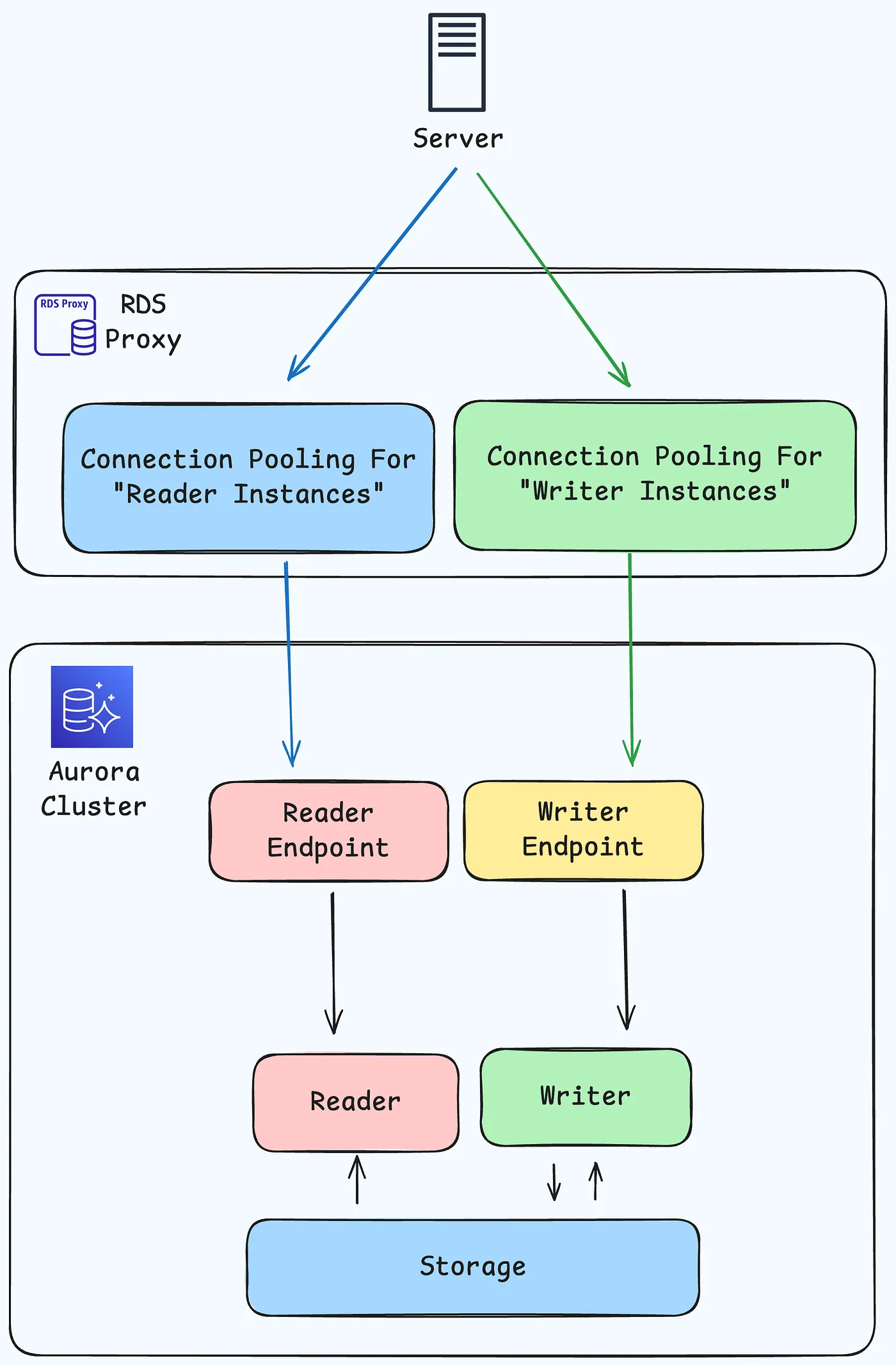
Using RDS Proxy with Aurora global databases
Primary Cluster (Active Writer & Readers)
- 读取/写入代理端点 → 将查询路由到写入实例。
- 只读代理端点 → 将查询路由到读者实例。
- 如果读取实例失败,RDS 代理将流量重定向到另一个可用的读取实例
Secondary Cluster (Read-Only Replicas)
- 只读代理端点 → 将查询路由到读者实例
- 读写代理端点 ❌ 失败,因为没有写入者实例存在
Failover or Switchover Process
- secondary集群被提升为primary
- 新primary集群的代理现在处理写入操作
- 旧主集群的代理仍然接受写入,但当集群变为次要时,写入会失败
- RDS 代理排队写入请求,并在新的写入实例可用时将它们发送过去
Aurora zero-ETL integrations with Amazon Redshift
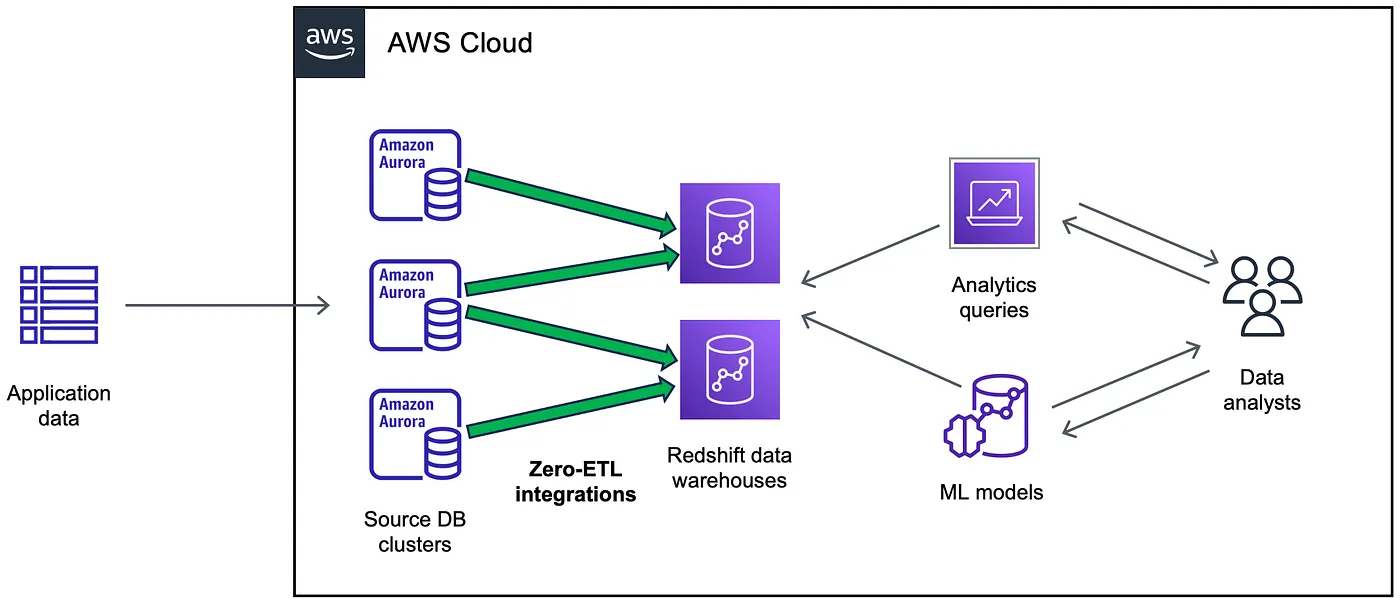
零 ETL 集成可以在近乎实时的情况下,将 Aurora DB 集群中的数据在 Amazon Redshift 中可用。一旦数据进入 Amazon Redshift,您就可以使用 Amazon Redshift 的内置功能来支持您的分析、机器学习和人工智能工作负载,例如机器学习、物化视图
要创建零 ETL 集成,将 Aurora 数据库集群指定为源,将 Amazon Redshift 数据仓库指定为目标。该集成将数据从源数据库复制到目标数据仓库
Using Amazon Aurora machine learning
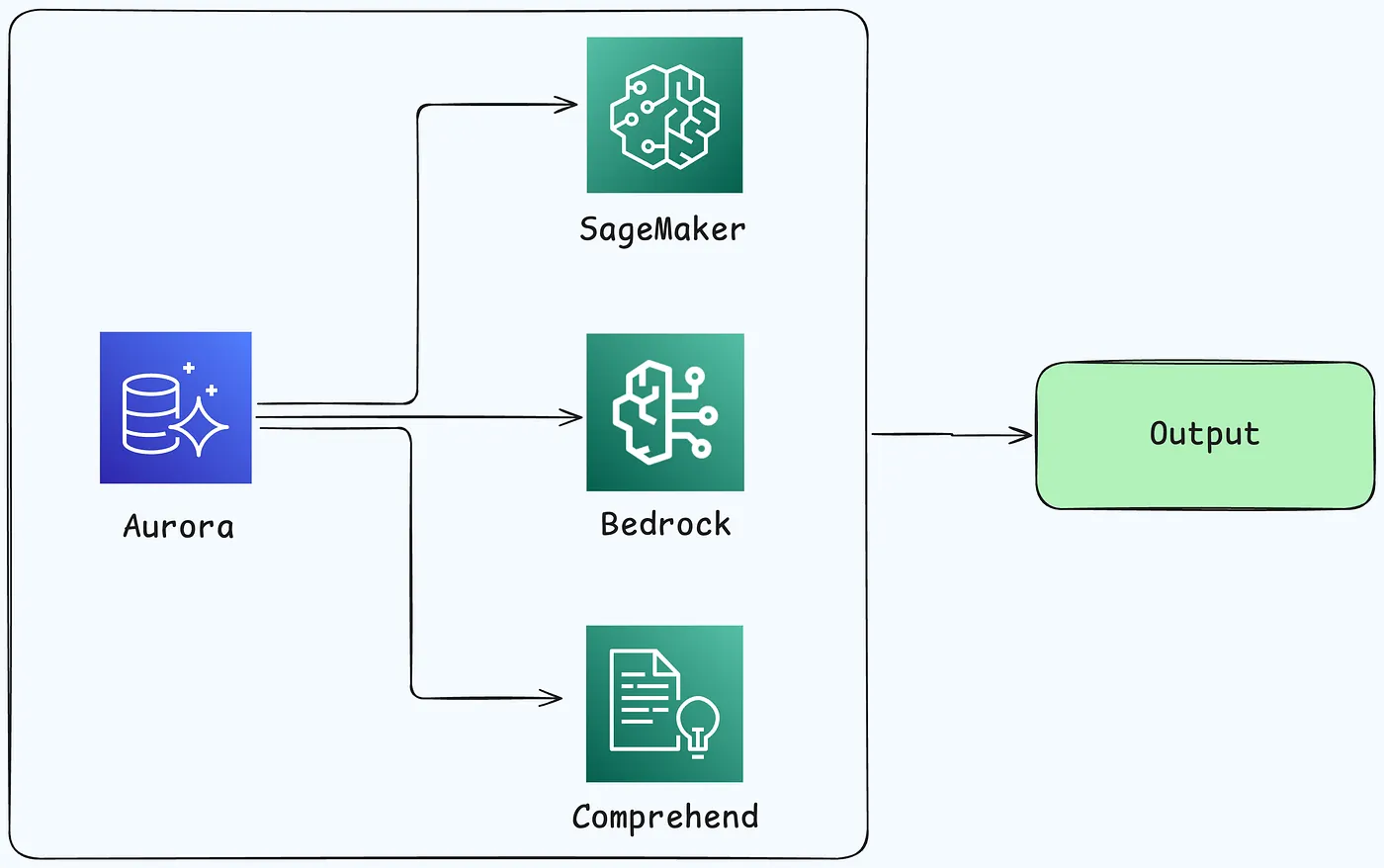
Amazon Comprehend — Text Analysis
SELECT review_id, review_text, aws_comprehend_detect_sentiment(review_text, 'en') AS sentiment FROM product_reviews;Amazon SageMaker — Custom Model Predictions
SELECT transaction_id, amount, card_holder,
aws_sagemaker_predict('fraud-detection-model', amount, card_holder) AS is_fraud
FROM transactions;
- Amazon Bedrock - Generative AI and Large Language Models
SELECT product_id, product_name,
aws_bedrock_generate('product-description-model', product_name) AS description
FROM products;
上述直接的调用,需要考虑延时的影响。
总结
我们探讨了与 Aurora 相关的基本方面,深入了解了其支持的四种数据库类型:
Provisioned Databases — 传统、托管数据库,配备专用资源 Limitless Databases — 设计用于高可扩展性和自动扩展 Global Databases — 跨区域复制,用于灾难恢复和低延迟访问 Serverless V2 Databases — 按需扩展,采用按使用付费模
这些数据库类型服务于不同的使用场景,Aurora 是一个庞大而复杂的话题
掌握 Aurora 不仅可以帮助你优化数据库性能,还可以使你在云端构建更具弹性和可扩展性的应用程序